


JavaScript中的event.stopPropagation方法用于阻止事件冒泡,这样该事件不会继续向上级元素传递。
不过今天我想讲的是event.stopImmediatePropagation,它除了具有event.stopPropagation方法的阻止事件冒泡的功能外,还有另一个功能,就是会中止执行在它后面添加/执行的同类型事件。也就是说干完我这件事件,后面的同类型的事情就都不用干了。
示例:
document.body.addEventListener("click", function () {
console.log("1");
});
document.body.addEventListener("click", function (ev) {
// 在它后面添加的同类型函数不会再执行了,但是早于它添加的函数还是会执行
ev.stopImmediatePropagation();
console.log("2");
});
document.body.addEventListener("click", function () {
console.log("3");
});
本来,由addEventListener添加的同类型事件会按照添加的顺序依次执行。这个例子中就是点击页面会依次输出1、2、3。
在2中加了ev.stopImmediatePropagation()之后,第二个添加的事件执行完,后面添加的同类型事件就不会执行了——不会输出3了。
注意:
1.stopImmediatePropagation方法会阻止的是同类型的,比如在click事件里执行了stopImmediatePropagation方法,并不能阻止在其后添加的其他类型的事件。
2.在执行stopImmediatePropagation的事件里,在stopImmediatePropagation后面的代码依然会执行。(如上例会继续输出2)。
ps:jQuery有个event.isImmediatePropagationStopped方法来检测该事件上是否设置了stopImmediatePropagation方法。但是原生JavaScript里好像没自带这个检测的方法。
JavaScript中每个函数都有call()和apply()方法(呼叫和申请 XD),这两个方法都是为了改变函数的this值。简单地说,如果一个对象没有某个方法,但是其他人有,那么就可以用call()或apply()来借用这个方法。
call()和apply()方法的参数都分为两个部分,第一个参数是要作为this的对象,其他参数是要借用的函数的参数。
如果第一个参数为null或缺省,就会把this指向全局对象(window)。
如下代码:
var a={
name:"saber",
say:function () {
console.log(this.name);
}
},
b={
name:"我是2b"
};
a.say.call(b);
a有个say()方法,可以说出自己的名字,但b没有这个方法。我们用a的say方法来call(呼叫)b,说我也不是谦虚,还是你来吧。这样a的this就变成了b,this.name也就是b的name了。
操作NodeList时常常借助数组的方法,代码如下:
var img=document.querySelectorAll("img");
[].slice.call(img,0,5);
[].forEach.call(img,function (no) {
console.log(no.src);
});
//[]相当于Array.prototype的简写
闭包是指有权访问另一个函数作用域中的变量的函数。
不用闭包的话,在函数外操作函数内的局部变量是不行的,因为局部变量的作用域只在函数内。我们可以通过闭包解决这个问题。
创建闭包的常见方式,就是在一个函数内部创建另一个函数,这样,被创建的函数就可以访问这部分作用域。
从形式上来说,给外部变量返回一个function,就形成了一个闭包。
function b() {
var a=1;
return function () {
console.log(a);
};
}
var c=b();
c(); // 1
上面代码是给外部变量c赋值了一个函数,可以输出函数b里面的变量a。
除了用return创建函数,我们也可以直接赋值。
如下代码,函数内有一个局部变量a,我们通过闭包,可以在函数外设置和读取a的值。
var set,get;
(function () {
var a=0;
set=function (s) {
a=s;
console.log(a);
};
get=function () {
console.log(a);
};
})();
set(2);
get();
使用闭包需要注意的问题有:
内存占用增加
this的指向。
如果想要防止自己的网页被别人用iframe给引用过去,可以在Header里设定X-Frame-Options。
示例:
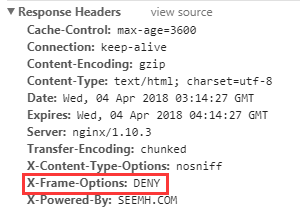
X-Frame-Options有3个值:
DENY
浏览器拒绝当前页面加载任何Frame页面
SAMEORIGIN
frame页面的地址只能为同源域名下的页面
ALLOW-FROM http://em.com/
这个网页只能放在http://em.com//网页架设的iFrame内
除了由服务器设置,网页也可以通过meta信息来设置,如:
<meta http-equiv="X-Frame-Options" content="deny">
pixiv的网页对于iframe就做了同源设置,如果在其他网站里试图将iframe的src设定为p站的url,是无效的。控制台报错信息如下:


本文略微记录一下开发chrome扩展的经验,免得以后用到了还要再去查一遍文档。注意这不是教程,只是一点人生的经验……教程可以参考这里。
1.文件结构:
在扩展的根目录必须有个manifest.json文件,这个文件很重要,参数可以去文档里看。
其他的所有文件可以放在根目录,也可以建立文件夹存放。
扩展的图标可以用jpg或者png格式;官方建议是不要把图标占满画布,而是在四周留下一点空白。
一般我们需要一个在后台默默运行的js,通常叫做background.js,它能使用所有chrome扩展的API。
通常我们也需要有一个在前台运行的js,可以叫做content.js。这个js会被加载进前台页面执行,它只能使用很少的chrome扩展的API。而且它通常只能访问dom结构,不能直接使用页面上定义的函数。
如果需要也可以建立一个活动页面,一般叫做popup.html。
如果需要也可以建立一个选项页面,一般叫做options.html。
以上这些都需要在manifest.json里定义。
其他的文件可以自行发挥,比如html文件、css文件、图片等,有需要就可以建立,然后自行调用即可。
在background的参数里设置"persistent": false可将扩展作为event page,可以减少一些内存占用。
Read More →
如果我们要删除一个DOM节点,可能大家都会想到remove方法。如下:
var a=document.createElement("a");
// 设置内容等代码 ...
a.parentNode.removeChild(a);
Node.removeChild() 方法从DOM中删除一个子节点。返回删除的节点。
从返回值是个节点我们可以知道,removeChild之后,这个节点虽然在DOM里去掉了,但是它仍然存在在内存里。
虽说过一段时间不用,它就会被浏览器回收掉,但如果要重复的创建这个节点的话,那么每次removeChild时使用delete操作符,可以略微优化内存占用(大概……)。
如下:
var a=document.createElement("a");
// 设置内容等代码 ...
delete a.parentNode.removeChild(a);
今天我在chrome上做了多次实验,有一些发现:
1.使用delete之后,chrome浏览器并不会立即回收这部分内存,而是等差不多二十秒之后才回收。
2.使用delete之后,内存回收的比只remove要多一些。
3.即使使用delete,内存也不能完全回收,内存占用还是会一直增加。只是情况略有缓解。
4.有人说delete回收内存只能回收由JavaScript创建的节点,如果是原本html文档里的节点,delete是回收不了的。我试了试,对于原本html文档里的节点,用delete和只用remove没看出明显区别,大概这个说法是对的。
如果我们要在网页上处理图片,对于字符形式接收到的图片(比如用ajax获取的图片)可以将其转换为blob对象。但对于img标签(或通过new Image()对象获取的图片)来说,它们不是字符形式,而是html元素,不能转换成blob对象。
要使用这样的图片,我们可以先将图片绘制到canvas里,再使用canvas对象的toDataURL方法获取图片的base64编码(也就是data: URI)。
ps:blob对象和data: URI都可以用a标签的download属性来下载图片~
1.如下代码展示用image对象获取一张图片并转换为base64:
var dataURL="";
var Img = new Image();
Img.crossOrigin = "Anonymous";
Img.src="/f/head15.jpg";
Img.onload=function(){
var canvas = document.createElement("canvas");
canvas.width=Img.width;
canvas.height=Img.height;
canvas.getContext("2d").drawImage(Img,0,0,Img.width,Img.height); //将图片绘制到canvas中
dataURL=canvas.toDataURL('image/png'); //转换图片为dataURL
};
注意image对象的crossOrigin 属性:
Img.crossOrigin = "Anonymous";
它在下面的情况中是有用的:
图片跨域了,但有个好消息是图片的服务器允许跨域。这时你加上这个crossOrigin属性就ok了,图片可以正常用。
但如果图片跨域了,并且图片的服务器【不允许】跨域,那你加上也没用,无解。
如果没解决跨域限制,canvas.toDataURL方法将报错,导致程序终止:
Uncaught DOMException: Failed to execute 'toDataURL' on 'HTMLCanvasElement': Tainted canvases may not be exported.
2.如下代码展示从页面上的img标签获取图片内容,并将其转换为base64:
// 记得要在图片加载完成后执行
var image=document.querySelector("img"),
canvas,
dataURL;
image.onload=function () {
canvas = document.createElement("canvas");
canvas.width = image.width;
canvas.height = image.height;
canvas.getContext("2d").drawImage(image, 0, 0);
dataURL=canvas.toDataURL('image/png'); //转换图片为dataURL
};
3.如果我们是要把图片用于下载的,那么对于色彩复杂、宽高较大的图片,用png格式显然体积会很大,可以转换成jpg的:
dataURL=canvas.toDataURL('image/jpeg',0.5);
经试验完全可用。另外chrome的话还可指定为 image/webp 。
4.扩展:现在各大浏览器只支持转换成png和jpeg格式,如果需要gif格式或bmp格式怎么办呢?可以用canvas2image.js。
canvas2image支持将canvas里的图片数据转换为png、jpeg、gif、bmp格式,并可修改生成的图片的宽高。
你可以仅转换但不下载,也可直接下载。like this:
Canvas2Image.saveAsImage(canvasObj, width, height, type) Canvas2Image.saveAsPNG(canvasObj, width, height) Canvas2Image.saveAsJPEG(canvasObj, width, height) Canvas2Image.saveAsGIF(canvasObj, width, height) Canvas2Image.saveAsBMP(canvasObj, width, height) Canvas2Image.convertToImage(canvasObj, width, height, type) Canvas2Image.convertToPNG(canvasObj, width, height) Canvas2Image.convertToJPEG(canvasObj, width, height) Canvas2Image.convertToGIF(canvasObj, width, height) Canvas2Image.convertToBMP(canvasObj, width, height)
html5对a标签新增了download属性用于下载文件,简单的理解是a标签如果添加了download属性,那么点击它的时候就不会跳转,而是会触发浏览器下载文件。如:


但firefox有点麻烦,它有同源限制,如果href里的url和当前页面的url不是同源就不能下载。

其他几大浏览器都没这限制(Edge、Chrome、Opera)。
另外firefox在由download属性触发下载时,可能会提示处理方式:
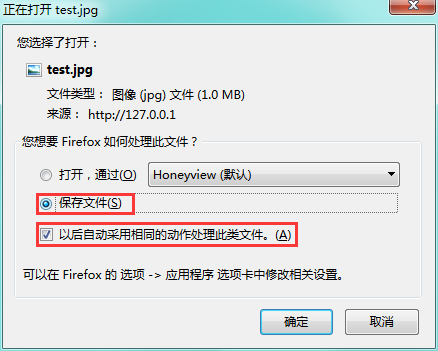
这好像是firefox下载文件时特有的提示,chrome没这个提示。
实际上firefox麻烦事还挺多,参见本文结尾的dwmo。
其他资料:
2.谷歌开发文档的非官方中文版
3.360极速浏览器的官方开发文档
翻译成了中文,挺不错,但是很久没更新,显得落伍了。
4书籍《Chrome扩展及应用开发》,我们可以在图灵社区免费阅读。这本书很不错。
这本书还有第二版,修订和增加了一些内容,不过不提供全部免费阅读。图灵社区页面
css的display: inline-block是替代浮动(float)的一个好办法。inline-block布局不会有float的一些缺点:脱离文档流、破坏inline box(具体来讲就是float的元素要等高,否则下面的float元素会被上面的卡住)。inline-block不会脱离文档流,元素高度不同也不会卡住。但是inline-block的元素之间会有空隙。
如下代码:
<div id="a"></div>
<div id="b"></div>
<style>
#a,#b{width: 100px;height: 150px;display: inline-block;}
#a{background: #0c0;}
#b{background: #0ff;}
</style>
两个div都是inline-block布局,默认会有空隙:
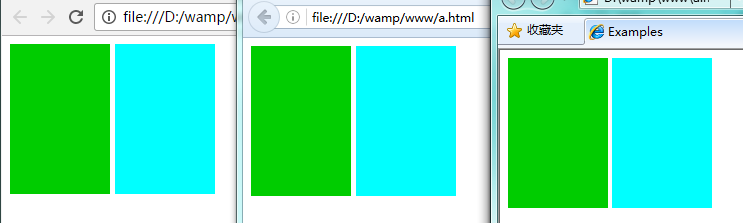
(IE8的空隙还比其他浏览器少了1px)
那怎么办呢?有两个解决办法:
1.使两个元素的代码之间没有空隙。如上例,则时两个div的代码挨在一起,中间不要换行。这样就没有空隙了。
2.给应用了inline-block布局的元素的父元素添加css属性:font-size: 0; 这样就OK了。
以上两个方法都兼容所有浏览器。
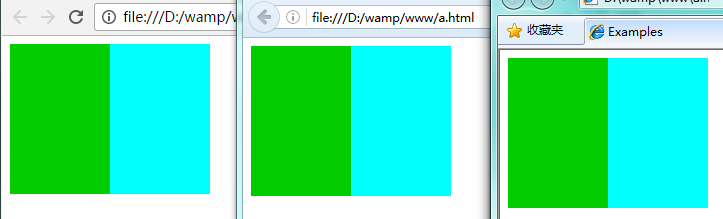
ps:以前chrome不吃font-size: 0;这一套,不过较新版本的chrome也支持了。
