


在以前,要使用JavaScript来操作DOM节点的class属性比较麻烦,很多时候都要借助第三方js库。但html5新增的classList对象使这一操作变得简便多了,而且这个对象已经实现了五六年了,浏览器兼容性也比较好。(IE从IE10开始支持,其他浏览器支持得更好)
在html5中,每个DOM节点都有个classList对象,我们可以借助该对象的方法、属性来便利的操作节点的class属性。
浏览器能力检测:
"classList" in document.createElement("a");
// in 操作符用于检测索引是否在该数组中,或属性是否在该对象中。判断的是key不是value
classList对象的属性和方法如下:
element.classList.length // 返回节点的class数量
element.classList.value // 返回节点的所有class名,等价于element.className
element.classList.add(string) // 给节点添加class。示例:
document.body.classList.add("c1"); // 添加一个class
document.body.classList.add("c1","c2","c3"); // 添加多个class
element.classList.remove(string) // 从节点删除class,语法同add()
element.classList.toggle(string) // 切换添加/删除class。如果不存在该class则添加,否则删除
// 如果执行的是添加操作则返回true,如果执行的是删除操作则返回false
// toggle方法可以有第二个参数,根据第二个参数的结果是true还是false来添加/删除该class
element.classList.contains(string) // 检查节点是否含有指定的class
element.classList.item(number) // 返回指定索引的class的名字
// 其实这个方法比较麻烦,一般情况下我们可以直接在element.classList后面用序号查询。如下操作是等价的:
document.body.classList[0];
document.body.classList.item(0);
// 区别在于如果参数指定的class不存在,它们的返回值不同
document.body.classList[1000]; // undefined
document.body.classList.item(1000); // null
前几天我对数据库进行了一次批量修改,但是今天发现有些地方改出了毛病,需要针对这些地方再进行修改。
什么问题呢?就是内链变成了以“/”开头的链接。问题在于http后面只有一个斜杠,所以要修复这个问题。
但是修复时还有个问题,就是如果直接匹配“/”的话,正常链接的“http://”也会被匹配到。为了避免这种失误,我只好尝试用正则表达式来解决。
我对着教程折腾许久,终于用术语叫做“零宽度负回顾后发断言”的方式达成了目标,累觉不爱。
/{1}+(?!/{1})
// 意思是 匹配“/”,但需要它后面不再有其他斜杠
然后我就去MySQL里用这个正则去查询一下试试:
select post_content from wp_posts where post_content REGEXP '/{1}+(?!/{1})';
// 报错 SQL错误(1139):Got error 'repetition-operator operand invalid' from regexp
emmmmm……上面的语法没错,但是问题在于MySQL对正则表达式的支持很简单,不支持零宽断言,所以悲剧了。所以这篇文章不幸成了反面教材……
后续:
我用了笨办法,先导出数据库,用文本编辑器替换之后再导回去,姑且也算解决了问题(逃
以前我网站上的图片是放在七牛图床上的,可以在七牛后台上传文件。但现在我的网站上没有这个功能(我不想用WordPress添加文章时的上传功能),每次添加图片都要远程登录服务器,再把文件放到附件文件夹里,非常麻烦。所以我今天做了个简单的上传文件的功能。
选择文件:
上传结果:

把下面的代码保存成php文件再访问就可以啦~
Read More →

昨天我在初音社(www.mikuclub.cn)看到了这个效果,有些地方的图片在鼠标经过时会放大,感觉很棒,整个网页似乎生动了不少,今天我也给自己的网站添加上了这个效果。
首先分析一下原理:在图片外层套了一个容器,这个容器和图片大小一样,设置超出隐藏。然后给图片添加上放大效果就可以了。
不过初音社应用这个效果的地方的宽高是固定的,但本站文章里的图片宽高是不一致的,所以需要用JavaScript来设定外层容器的宽高。
实现步骤如下:
首先添加css样式:
.img_scale_wrap{overflow: hidden;} /*外层元素*/
.post_t img{transition:1s;} /*设置过渡时间*/
.post_t img[data-scale]:hover{transform: scale(1.2);} /*放大效果*/
然后添加JavaScript代码:
var post_img = document.querySelectorAll(".post_t img"); // 获取所有图片
if (post_img.length > 0) {
// 给图片添加缩放控制层
function set_post_img_wrap(img) {
if (img.height>=500) { // 大于一定尺寸的才添加放大效果
img.setAttribute("data-scale", ""); // 添加放大属性
var post_img_wrap = document.createElement("div");
post_img_wrap.className = "img_scale_wrap";
img.parentNode.insertBefore(post_img_wrap, img);
post_img_wrap.appendChild(img);
post_img_wrap.style.width = img.width + "px";
post_img_wrap.style.height = img.height + "px";
}
}
// 给图片添加事件
for (var i = post_img.length - 1; i >= 0; i--) {
if (post_img[i].complete) {
set_post_img_wrap(post_img[i]);
} else {
post_img[i].onload = function() {
set_post_img_wrap(this);
}
}
}
}
本文的代码也可以用在其他类型的网站上,不只是WordPress里才能用。但是移植时要按自己情况修改css选择器和js选择器。
数据库的备份与恢复是个常见的问题,但是不同备份工具备份出来的.sql文件内容与格式不尽相同。
对于phpMyAdmin导出的sql文件,似乎用phpMyAdmin恢复比较容易。但我用其他一些MySQL数据库管理工具经常无法恢复成功(如使用Navicat for MySQL、HeidiSQL运行转储的sql文件,没有任何效果)。今天我试了下用MySQL命令行恢复phpMyAdmin导出的sql文件,感觉比较好使,记录一下。
恢复之前先手动创建一个空的数据库,编码和排序方式按需要选择。比如dedecms和WordPress默认的都是utf8_general_ci。
之后运行MySQL命令行,输入密码开始使用。
之后依次输入命令(按需要修改):
use databasename; set names utf8; source d:\desktop\simple.sql;
如下:
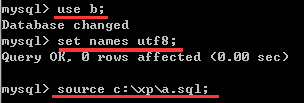
记得输入分号,否则第二个命令会跑偏。
输入第三条之后就开始恢复了,等到执行完毕就ok了。
其实前两条命令,有些工具导出的sql文件里已经有了,有的没有(phpMyAdmin导出的就没有,这应该也是直接运行它备份的sql文件时无法恢复数据的原因)。所以有些工具备份的sql文件可能比较容易恢复,有的就要手动输入命令了。
自动解除ikanman.com上被屏蔽的漫画。当你在ikanman上看漫画时,country会被设置为US,以此解除屏蔽。
被屏蔽的漫画示例:《出包王女Darkness》
ps:本脚本分离自 《仙尊ikanman、omanhua漫画下载器》,如果你安装了这个下载器,就不需要再安装本脚本了。
被屏蔽时:
自动解除屏蔽:
如果我们在JavaScript里想输出一个script标签,可以这样写:
document.writeln("<script>alert('xx');</script>");
但如果是在html文件里的script标签里这样写,就会出现语法错误:
<script>
document.writeln("<script>alert('xx');</script>");
</script>

在编辑器里面也能看出来异常,本来红框内是字符串,应该都是黄色的,但是显示的不对,原因就是在html里会把结束标记的字符串
“</script>”解析成标签,导致了错误。
解决办法是把导致错误的这个结束标记拆开再拼接起来:
<script>
document.writeln("<script>alert('xx');</scr"+"ipt>");
</script>
织梦(dedecms)后台默认首页是动态网页,其余栏目页、文章页是静态网页。
静态化有利于减小服务器压力,但是在开发、调试的时候,修改完网站需要更新网页才能看到效果,不如使用动态化来得便捷。
要切换静态。动态页面,步骤如下:
1.首页
①:静态改动态:
如果首页一直保持的是默认的“动态浏览”,则无需改动。
如果首页之前已经改成静态化了,在后台设置里改成“动态浏览”,再删除网站根目录里的index.html就行了(之后访问首页网址,如果后面还带的有index.html,是浏览器缓存的原因,实际上已经动态化了)。
2.栏目页
执行以下SQL语句把所有栏目页设置为动态化:
update dede_arctype set isdefault=-1
如果最后改为1,则是静态化。
3.文章页
执行以下SQL语句把所有文章页设置为动态化:
update dede_archives set ismake=-1
如果最后改为1,则是静态化。
如果最后改为0,则是伪静态。但织梦的伪静态我还没用过,不知道是什么样。
ps:栏目页和文章页都可以在最后加上 where typeid=1 的形式来修改指定栏目的设置。
商务通可以定制中间邀请框,用一个图片取代原来的邀请框。但是这个图片的url是定制的时候固定死的,后面要再改就要再花几百块。不过我们可以用JavaScript来替换图片url。
// 重设商务通中间定制图片的url
setInterval(function () {
try{ //如果检查到中间图片,则替换其src
document.querySelector("#LRdiv1 img").src="http://www.my.com/swt_center.gif";
}catch(err){
console.log(err.message);
}
},1000)
今天做的网站上有个地方的单选按钮是这样的:

这个需要做美化,我找到了一个办法,步骤如下:
1.先把按钮隐藏,然后放一个i标签来伪装成按钮。把我们自己做的按钮图片设置为i标签的背景图。
2.按钮被隐藏起来了,怎么选中/反选按钮的状态呢?这就需要用label标签把按钮、i标签以及文字包裹起来,这样点击i标签和文字就可以设置按钮的选中状态了。
html代码如下:
<label><input type="radio" name="sex" value="男" checked><i></i> 男</label> <label><input type="radio" name="sex" value="女"><i></i> 女</label>
3.在按钮的选中状态改变后,css怎样能相应的改变图片呢?我原以为要用js来判断选中状态,不曾想css里也有对应的选择器了。
css代码如下:
input[type="radio"] {display:none;} /*隐藏按钮*/
label i { } /*设置通用样式,如宽高等*/
input[type="radio"] + i { } /*这里设置未选中时的背景图,内略*/
input[type="radio"]:checked + i { } /*这里设置选中时的背景图,内略*/
这是什么操作?我查了下,原来这是 :checked 是一个css3的伪类选择器,可以匹配每个选中的输入元素(仅适用于单选按钮或复选框)。
除此之外还有个识别禁用状态的 :disabled 伪类选择器,这次我没有使用。
+号选择器则代表相邻的元素。
Read More →
