


通过使用css的after、before伪元素,我们可以对html元素追加内容。今天我在对img元素使用after、before伪元素时发现不生效,后来确定是after、before伪元素对于img标签这类不支持内嵌其他标签的标签无效。
如下图,是对p标签使用after,正常。
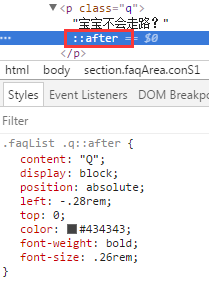
注意,如果生效的话,我们在开发者工具里能看到红框处添加了伪元素。
下面是对img元素使用after,css规则是正确加载了的,但是没有给img标签追加伪元素。
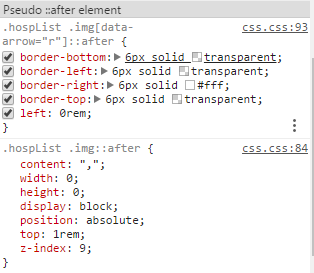
后来我思考了一下,发现伪元素生效时,在html里追加的伪元素是位于标签内的。但img标签不能再嵌套其他标签,所以这时候伪元素就不生效了。
以此类推,其他一些不能嵌套子元素的标签应该一样不能使用after、before伪元素。
后来我去MDN上看了看这俩伪元素的定义,确实是这样。国内的一些网站上的资料则是说在元素前/元素后追加伪元素,害人不浅。
dedecms(织梦)的文章在修改后不会自动更新文章简介。我们可以用下面的办法清除简介并重新生成:
首先在 系统→SQL命令行工具里,执行如下语句:
update dede_archives set description="";
然后到 核心→批量维护→自动摘要|分页 里面批量生成摘要即可。
现代浏览器都支持html5的video标签,在网页中插入视频和播放视频都变得非常简单。但是要兼容IE8的话则比较麻烦,因为IE8不支持video标签,还得使用flash播放器来播放视频。难道因为IE8的拖累,我就只能使用flash播放器了吗?
当然不是,理想的解决方案是在现代浏览器上使用原生video标签,在低版本IE浏览器上使用flash播放器。html5media就是这样一个视频解决方案,我们只需要写标准的video标签就行了。在低版本IE浏览器里,html5media会自动调用flowplayer这个flash播放器进行处理,非常的方便。
使用步骤:
1.下载html5media的压缩包,然后找到dist→api文件夹,把要使用的api文件夹复制到项目文件夹里。
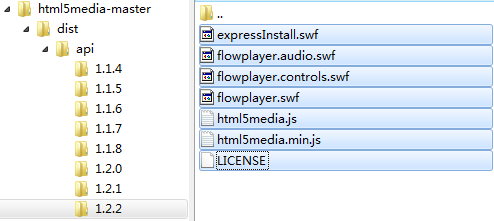
2.在网页上引用html5media的js文件:
<!--[if lt IE 9]> <script src="path/html5media.min.js"></script> <![endif]-->
这样,在IE8及更低版本的浏览器里,就会引入html5media的js文件了。
再次提醒:要复制使用的api的整个文件夹,包括里面的几个swf文件,不然IE8里就歇菜了。
3.设置video标签。
<video src="/f/nico.flv" width="720" height="405" poster="/f/nico_poster.jpg" controls preload="meta"></video>
这样就完成了。
Read More →
说到ajax,不能不提到跨域限制这个问题。与跨域紧密相连的是referer,如果referer相同,就不会触发跨域限制;反之则视为跨域。
但发生跨域时,能否请求到跨域资源,也分两种情况:
第一种:服务器端不检查referer,这时候是否受跨域限制,由浏览器管理。
这时是否触发跨域限制,全由浏览器自己判断。比如在网页上用img标签插入一张跨域的图片,浏览器是不会触发跨域限制的,可以正常加载图片。但用ajax获取的话,浏览器就会触发跨域限制,获取不了。
这时候就算跨域了,服务器也是允许浏览器去下载文件的,只是看浏览器自己愿不愿意。
第二种:服务器端会检查referer,不符合规则的就拒绝。
这时候浏览器就吃瘪了,用img标签来插入图片也不行,这也是通常的防盗链手段。
如果我们在请求头里设置合法的referer,就可以破解跨域限制,但目前运行在浏览器宿主环境内的JavaScript实现不了这个功能,需要交给后台程序来做。如果只为了破解referer就单独做个后台文件,比较麻烦。但是我们使用油猴脚本的话,就不用写后台文件了,比较省事。
油猴脚本管理器(Greasemonkey或Tampermonkey等)由于是浏览器的扩展程序,可以设置请求头,包括伪造referer。它们都封装了一个GM_xmlhttpRequest方法,可以在用户脚本(UserScript)里调用。
今天我进行了测试,确定是可行的。示例代码如下:
// ==UserScript==
// @name test GM_xmlhttpRequest
// @description test
// @namespace https://greasyfork.org/ja/users/24052-granony
// @author me
// @version 0.1
// @include https://greasyfork.org/*
// @grant GM_xmlhttpRequest
// @connect i.pximg.net
// @connect i1.pixiv.net
// @connect i2.pixiv.net
// @connect i3.pixiv.net
// @connect i4.pixiv.net
// @connect i5.pixiv.net
// ==/UserScript==
GM_xmlhttpRequest({
method: "GET",
url: "https://i.pximg.net/img-original/img/2017/05/16/00/20/10/62921231_p0.png",
headers: {
referer: "https://www.pixiv.net/"
},
overrideMimeType: "text/plain; charset=x-user-defined",
onprogress: function(xhr) {
console.log(xhr.lengthComputable + "," + xhr.loaded + "," + xhr.total);
//xhr.lengthComputable:布尔值,是否可以获取到文件总长度
// xhr.loaded:已加载的字节数
// xhr.total:文件总字节数
},
onload: function(xhr) {
var r = xhr.responseText,
data = new Uint8Array(r.length),
i = 0;
while (i < r.length) {
data[i] = r.charCodeAt(i);
i++;
}
blob = new Blob([data], {
type: "image/png"
});
var blobURL = window.URL.createObjectURL(blob);
var downA = document.querySelector("h1 a");
downA.href = blobURL;
downA.setAttribute("download", "a.png");
downA.click();
window.URL.revokeObjectURL(blobURL);
}
})
上面代码的功能是下载一个跨域并且服务器设置了referer防盗链的文件,下载后将其转换为blob对象保存到本地。
首先要授予这个脚本调用GM_xmlhttpRequest的权限:
// @grant GM_xmlhttpRequest
但光这样还不够,还要在@connect里指定跨域获取文件时文件url里的域名。如果文件url的域名没有在@connect里指定,则GM_xmlhttpRequest会报错。
如果跨域文件没有设置referer防盗链,那么到这里就够了,跨域问题会被自动处理(。
但示例代码里的url有防盗链设置,而且比较奇葩,服务器要求的其实是个不同源的referer,同源的referer反而不行。这就需要我们在GM_xmlhttpRequest方法的headers参数里设置合法的referer了:
headers: {
referer: "https://www.pixiv.net/"
}
其实上面的代码里还有个挺纠结的地方,就是把接收的数据转换为blob对象的过程。
JavaScript原生的XMLHttpRequest对象和jQuery的ajax方法都可以设置把接收的数据自动转换为blob类型,如:
xhr.responseType="blob";
这样拿到的response直接就是blob对象,但这个办法油猴的GM_xmlhttpRequest里测试不行。我见到有的油猴脚本在GM_xmlhttpRequest里设置了:
responseType: "blob",
我试了也不行,不知道人家是怎么用的,反正我这里测试是不行……
后来我在github上找到了一个办法可以把接收的数据转换为blob对象,就是上面代码里用的,看着挺费劲。主要是做了三个工作:
1:请求前设置overrideMimeType;
2:onload之后用Uint8Array和charCodeAt将数据正确的转换为blob对象。
Uint8Array和charCodeAt和这俩我之前完全不认识,看到的时候一脸懵逼:


后来我深入了解了上面步骤的作用:
overrideMimeType告诉服务器需要返回无格式纯文本的mime-type,而不是image/jpeg、image/png等图像格式。
Uint8Array是创建一个指定长度的无符号数组,charCodeAt则用来把response逐字节转换为Unicode编码(response都是string)。
怪不得我之前简单粗暴把response放进数组里转换成的blob对象有问题,还是姿势太低。
其他参考资料:Greasemonkey wiki
我之前的sitemap文件里有很多链接是错误的,早期的时候本站页面还没有启用伪静态,那时候文章网址后面没带.html。今天我写了个代码来自动抓取本站的所有文章,并生成sitemap字符。
这个代码可能仅适用本站使用的clearision模板。用在其他模板或其他类型的网站的话可能就需要略作修改了。
ps:
WordPress最近更新后,本文的代码失效了。可能是因为WordPress把短链接做了301跳转导致抓取不到。现在使用《网站地图生成助手js版》
在pc设备上,我的博客底部会有一个saber桌宠走来走去~这个效果大概是三年前博客建立不久就做了,但是当时是用JavaScript的定时器来改变桌宠的位置的。今天我把它用css3动画重做了一遍,效果基本上维持原样。
这次我依然用到了JavaScript,不过JavaScript已经不直接移动桌宠的位置了,它的作用是动态创建animation动画规则,这样桌宠的移动就由css3动画控制了。
其实我改成css3动画本来是想降低我的博客在浏览器里的资源占用,但是改了之后发现效果不明显,看来占用资源大头的另有原因,这个以后再查吧。
Read More →
document.hidden是HTML5里一个新增的属性,它会返回一个布尔值,用来指示当前页面(标签页)是否可见。
比如说你正在看这个页面,那么document.hidden就会返回true。如果你切换到别的标签页去了,或者最小化了浏览器之类的情况,document.hidden就会返回false。
手动检测document.hidden灵活性很差,我们可以为document添加visibilitychange事件来监听页面可见性的变化。
document.addEventListener("visibilitychange", function (argument) {
if (document.hidden) {
alert("看不见看不见");
}else{
alert("二狗子你又回来了");
}
});
当然,上面的代码只是个示例,实际使用中不要照搬。因为当用户切换到其他页面时,这个页面就会弹窗“看不见看不见”。之后点掉弹窗,你就等于又切换回来了,这时候“二狗子你又回来了”百分之百触发←_←
visibilitychange的兼容性目前应该问题不大了,毕竟document.hidden都出现至少5年了,相关事件监听应该早就跟上了。
当然IE8是不要想了,它连document.msHidden都不支持。
三大浏览器的私有属性和方法示例如下(虽然对于不支持的老IE还是没办法):
var visibilityChange;
if (typeof document.hidden !== "undefined") {
visibilityChange = "visibilitychange";
} else if (typeof document.mozHidden !== "undefined") {
visibilityChange = "mozvisibilitychange";
} else if (typeof document.msHidden !== "undefined") {
visibilityChange = "msvisibilitychange";
} else if (typeof document.webkitHidden !== "undefined") {
visibilityChange = "webkitvisibilitychange";
}
document.addEventListener(visibilityChange, function() {
// code...
}, false);
前情提要:
《在JavaScript中创建Blob对象》
《使用canvas将图片转换为base64编码》
之前的这两篇文章都是为在网页上下载文件而服务的。Blob对象可以通过URL.createObjectURL(blob)方法来生成一个blob协议的url,而canvas可以通过canvas.toDataURL()来生成一个base64编码的url。这两种url都可以用a标签的download属性来下载。
注意:
将数据(包括canvas对象)转换为blob时,会受到跨域限制。
canvas酱图片转换为base64编码时也会受到跨域限制。
使用a标签下载文件时,在firefox里会受到跨域限制。
之前我没发现canvas对象是可以转换成Blob对象的,今天才知道有一个HTMLCanvasElement.toBlob()方法可以做到。
语法如下:
canvas.toBlob(callback, mimeType, qualityArgument);
说人话:
canvas.toBlob(function(blob) {
// code...
},"image/jpeg", 0.8);
toBlob方法内有一个回调函数,其参数就是canvas对象转换后的生成的blob对象;
如果缺少mimeType参数,则默认为png格式。
相比使用base64编码的url,blob格式的url更加简洁,我喜欢后者。不过base64编码其实储存的是文件本身,它方便重复使用。而blob对象则在刷新页面后就没了,blob格式的url也就不能重用了。
如下代码,先加载一个图片,然后将其绘制在canvas里,之后将canvas元素转化为blob对象,再用一个a标签来做下载功能。
var Img = new Image();
Img.src = "58319482.jpg";
Img.onload = function() {
var canvas = document.createElement("canvas");
canvas.width = Img.width;
canvas.height = Img.height;
canvas.getContext("2d").drawImage(Img, 0, 0, Img.width, Img.height); //将图片绘制到canvas中
canvas.toBlob(function(blob) {
var downloadA = document.createElement("a");
document.body.appendChild(downloadA);
downloadA.style.display = "none";
downloadA.setAttribute("download", "download.jpg");
downloadA.setAttribute("href", URL.createObjectURL(blob));
downloadA.click();
}, "image/jpeg", 0.8);
};
说到使用JavaScript选中文字,可能用得最多的场景是全选input输入框里面的文字,这个对input元素使用select()方法即可。
但是对于其他元素里的文字,select()方法无效,那么如何选中呢?浏览器中有Selection对象,我们可以通过Selection对象获取用户选择的区域,或者自动的去选择指定内容。
下面的代码是简单的示例,实现了选择某元素内的文本的功能。
function selectText(e) {
if (document.selection) { //ie
var range = document.body.createTextRange();
range.moveToElementText(e);
range.select();
} else if (window.getSelection) { //chrome firefox
var range = document.createRange();
range.selectNode(e);
window.getSelection().removeAllRanges();
window.getSelection().addRange(range);
}
}
selectText(document.querySelector("p"));
另外可在选择后使用document.execCommand来自动复制选择的内容:
document.execCommand('copy');
但要注意的是这个命令只能被用户手动操作来触发。
可参阅MDN文档
有时候,我们可能需要为不同国家的用户提供个性化服务,那么在浏览器里,我们可以使用JavaScript来获取UA里的语言设置,以此来判断用户的语言环境。
代码如下:
var language = navigator.language || navigator.browserLanguage;
if (language.indexOf('zh') > -1) {
language = "chinese"; //中文
} else if (language.indexOf('en') > -1) {
language = "english"; //英文
} else if (language.indexOf('ja') > -1) {
language = "japanese"; //日文
} else if (language.indexOf('nl') > -1) {
language = "dutch"; //荷兰语
} else if (language.indexOf('fr') > -1) {
language = "french"; //法语
} else if (language.indexOf('de') > -1) {
language = "german"; //德语
} else if (language.indexOf('it') > -1) {
language = "italian"; //意大利
} else if (language.indexOf('pt') > -1) {
language = "portuguese"; //葡萄牙
} else if (language.indexOf('es') > -1) {
language = "Spanish"; //西班牙
} else if (language.indexOf('sv') > -1) {
language = "swedish"; //瑞典
}
navigator.language是chrome和firefox所拥有的属性,navigator.browserLanguage则是IE独有。默认的话获取到的值是和操作系统的语言保持一致的,不过用户也可以在浏览器内自行更改。
