


还记得这个么
https://news.microsoft.com/zh-cn/%E5%BE%AE%E8%BD%AF%E5%92%8C%E7%99%BE%E5%BA%A6%E5%AE%A3%E5%B8%83%E7%99%BE%E5%BA%A6%E6%88%90%E4%B8%BA%E4%B8%AD%E5%9B%BD%E5%B8%82%E5%9C%BA-windows-10-%E6%90%9C%E7%B4%A2%E5%BC%95%E6%93%8E/
现在M$终于学会了如何做一个接地气的浏览器啦
http://bbs.pcbeta.com/viewthread-1754599-1-1.html
可以,这很特色#滑稽
// ==UserScript==
// @name 百度贴吧自动顶帖
// @namespace https://saber.love/?p=3695
// @version 0.1
// @description 隔一段不定的时间,发表一条回复。不支持楼中楼。
// @author 雪见仙尊
// @match https://tieba.baidu.com/p/11111111111*
// @grant none
// @run-at document-end
// ==/UserScript==
/* 使用说明:
帖子网址需要通过修改脚本的match规则,手动指定。
如果需要修改发表内容,直接修改下面的“自顶”两个字即可。
默认的时间范围大概在0-500秒之间
*/
function setAutoPost() {
var timer = parseInt(Math.random() * 500 * 1000);
setTimeout(function() {
$("#ueditor_replace p").html("自顶");
$(".poster_submit").click();
setAutoPost();
}, timer);
}
setAutoPost();
百度贴吧自动顶帖,电脑版。使用帖子最下面的回复框来回帖,不支持楼中楼。
如果临时使用,只复制下半部分的JavaScript代码,在浏览器控制台手动执行也可以。
说明:
帖子网址需要通过修改脚本的match规则,手动指定。
如果需要修改发表内容,直接修改下面的“自顶”两个字即可。
默认的时间范围大概在0-500秒之间。
嘛现在简中的winrar,在英文官方那下到的也是带广告的个人版了。放不放key都有广告。怎么办?
换用开源的7-z吧
其实网上也有官方的无广告版链接。万一哪天没有了怎么办?
参考http://bbs.pcbeta.com/forum.php?mod=viewthread&tid=1710775
1、 下载WinRAR(http://rarlab.com/)
2、 下载 Resource Hacker(http://www.angusj.com/resourcehacker/)
3、 用压缩软件打开WinRAR安装包,提取 WinRAR.exe
4、 用Resource Hacker打开winrar.exe
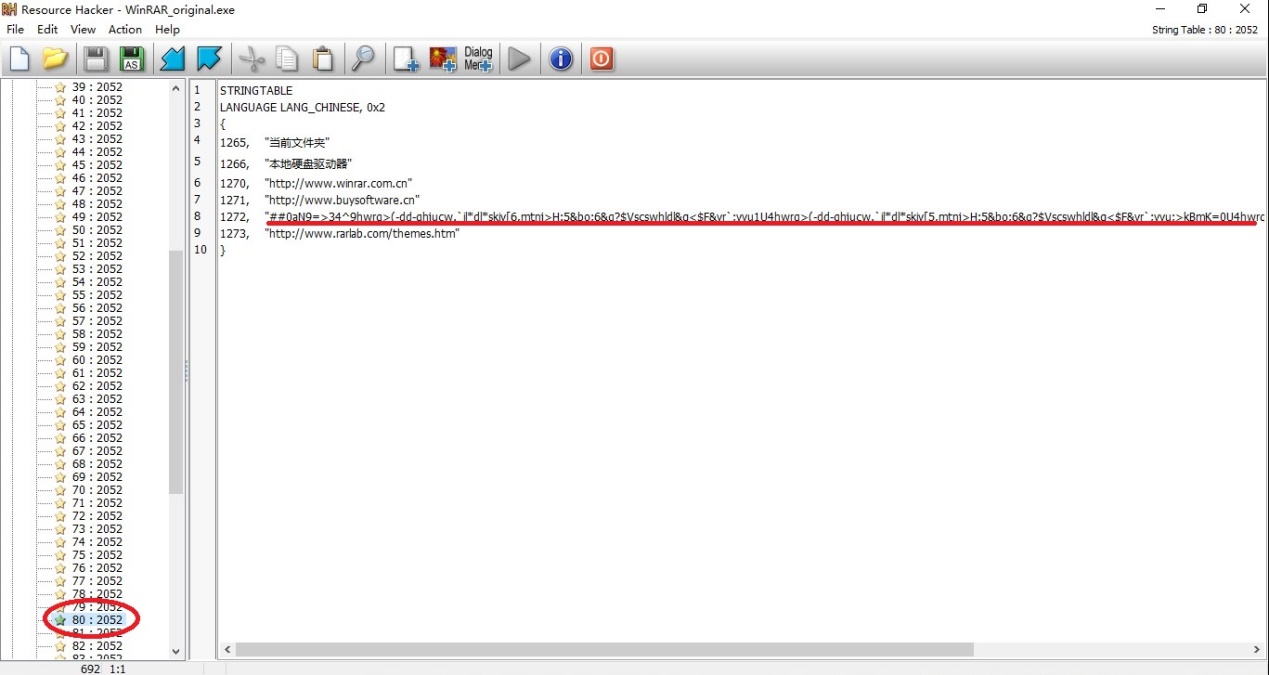
5、 在String Table下找到80 2052,然后在右侧的
1272,"##0aN9=>34_9hwrq>(-dd-qhjucw.`il*dl*skiv[6,mtnj>H:5&bo;6&q?$Vscswhldl&g<$F&vr`;svk`2Q;hwrq>(-dd-qhjucw.`il*dl*skiv[5,mtnj>H:5&bo;6&q?$Vscswhldl&g<$F&vr`;svk`14mLgA36^>hwrq>(-dd-qhjucw.`il*dl*skiv[5,mtnj>H:5&bo;6&q?$Vscswhldl&g<$F&vr`;svk`Z5"
删除引号内的任何一个字母、数字或符号。
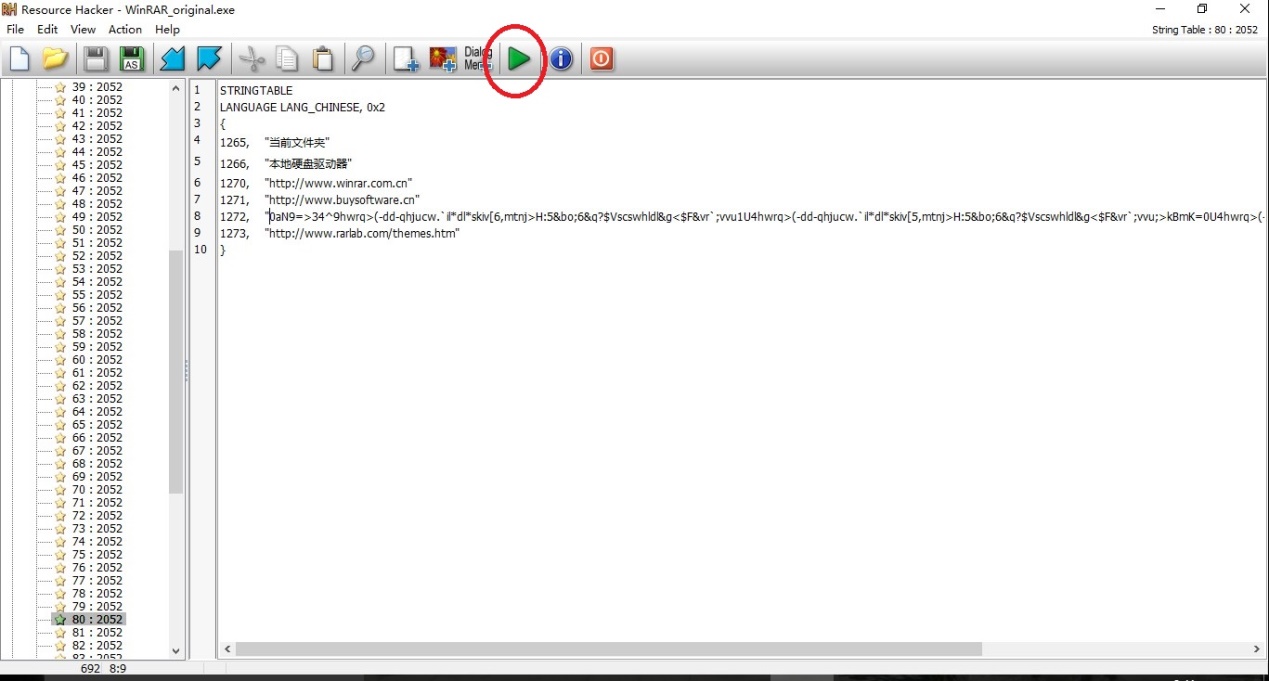
6、 点绿色箭头,然后保存即可,替换原始winrar.exe使用

生日快乐,公主殿下~
回想起来,我第一次认识初音(以前我习惯叫Miku)是2012年玩了初音的同人游戏(初音未来同人游戏三部曲)。游戏的开头和人型电脑天使心类似,都是捡到一个机器人妹子。我也想捡一个呢。 咪~
后来我收藏了很多Miku的pv(是歌姬计划里录制的视频,不是MMD),还有一些虚拟演唱会的录像。当时最喜欢的pv是《ハト》(鸽子),无忧无虑的海盗Miku太可爱了。要说最喜欢的歌曲的话,是《えれくとりっくえんじぇぅ》(电子天使),非常感人。
再后来,我开始看MMD,听更多的歌,逐渐对Miku了解的更多了。在今天,Miku 诞生10周年之际,就让我也小小的纪念一下吧~
生日快乐!

(图文无关)
[桜都字幕组]2017年8月合集:
magnet:?xt=urn:btih:31C18B50D1158390E42F8C5C8B24C7F950227BCA
[魔穗字幕组][2017年8月合集]
magnet:?xt=urn:btih:a5a974f05f1e291be4d94b0b3467d24530af3b45
目录:
[AniMan] 淫妖蟲 蝕 -孕ミ堕チル少女達- Anime Edition
ヌキどきッ!Revolution大和の妄想、大暴走!ののあが悪魔に着替えたら編
貴方ハ私ノモノ ―ドS彼女とドM彼氏―・下 立派なワンコへご褒美を
[ばにぃうぉ~か~]おいでよ!水龍敬ランド #1 はじめての水龍敬ランド
[PoRO]おいでよ!私立ヤリまxり学園 「おしめっ娘JK・静流~」
メンヘラ歩理のヤまないおねだり~ヘッドホンははずせない~ 2nd
炎の孕ませおっぱいエロアプリ学園 THE ANIMATION 第1巻
[QueenBee]いちごショコラふれーばー2[NAZ]
[BOOTLEG] 僕だけのヘンタイカノジョ THE ANIMATION_v2
如果需要度盘,可以到琉璃神社自行上车。
PS:有人总是说8月的爆了,不过我这里目前还可以正常下载的(2017/8/30)。实在不行就去用度盘的吧。


(图文无关)
[夜桜字幕组]2017年8月3D作品合集[BIG5+GB]
magnet:?xt=urn:btih:B3E946FF0560B45345A69751F2927F2D74EFB100
这个磁链我现在还是可以正常下载的。如果需要度盘,可以到灵梦御所自行上车。
说起来,这个合集里有《to love》里梦梦的那个3D视频,我放个系列传送门:
To LOVE-Ru Diary系列全部动画和游戏下载

这次的资源是《はにデビ! Honey&Devil》的提取CG。同样是画风很棒的社保之作。
磁力链接:
magnet:?xt=urn:btih:6B811EA18AE75B4123C27529A5ABFE4AA7813B08
度盘链接 提取码: vyyt
话说今天七夕啊,小水和我去滚床单吧o(* ̄3 ̄)o
部分预览:
Read More →
我今天在p站搜肯娘的图的时候,搜到了画师Mukka,感觉他的作品很棒,尤其是欧派……咳咳,最近的作品都是R-18图了,简直是wtmsb。今天我整理了下发个图包造福大众。
查看Mukka的pixiv
(最近画了很多Fate/Grand Order 的R-18图)
图包下载:
度盘链接 提取码: fy34
部分预览:(未成年人请勿入内)
Read More →
![[blue arrow garden] 作品合集下载 小悪魔シェリー2 ~新婚生活編~ 3D cg galgame H hentai 度盘 提取动画 游戏 福利 视频 资源](/f/小恶魔2-2.jpg)
其实我本来只打算发《小悪魔シェリー》系列的两部作品的提取动画的(上图为第二部封面),但是后来到制作公司blue arrow garden 官网 看了下,还有其他作品,我就找了找资源,一起发了。

《初情スプリンクル》是于2017年7月28日发售的一款Galgame,画风超赞,内容实用,用一句话来说就是wtmsb!
游戏本体磁力链接:
magnet:?xt=urn:btih:B3AE6771AF7F3FBEB45521E905B60BB01CCE17C6
提取CG 磁力链接(png格式):
magnet:?xt=urn:btih:3B1BC50125C31515148569B88939FB8CE2C76D60
提取CG 百度网盘(jpg格式):
https://pan.baidu.com/s/1dFJ7VXJ 提取码: ygbq
以上链接如有失效,可到btdb.to自行查询可用链接。
部分CG预览图(未成年勿入):
Read More →
