


前两天做的项目中使用了SuperSlide,做了个焦点图切换效果和图片向左滚动展示的效果。使用时参照官方demo做了些细微改动,现在我再把代码单独存一份,方便以后使用。
1.焦点图切换(通屏):
2.图片向左滚动:
这是一款局域网ip扫描工具,通过扫描指定的端口来判断该ip是否在使用中。
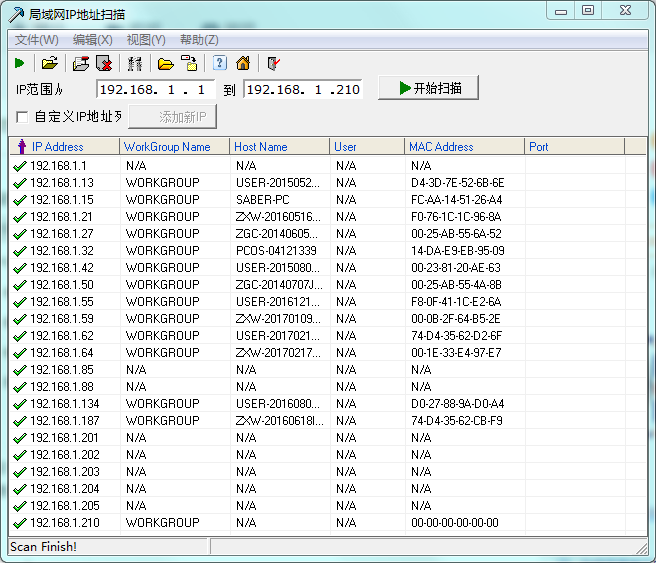
我试了一下,感觉还不错。1.1是路由器,15是我电脑的ip,85和88这俩我也不知道是什么设备。201-204是无线路由器,205是什么鬼,是我设置的吗?210是打印机的ip。
这个软件默认似乎是会显示未响应的ip的,也就是1-255会全部显示出来。我上面这样是去设置里改了。大家也可以去设置里按照自己的需求更改设置。
当我们在chrome的地址栏中输入内容的时候,chrome会在历史记录、书签里寻找匹配的内容并加以提示。
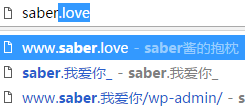
如上图,我只输入了“saber”,chrome便显示出了我访问过的一系列网址,如“www.saber.我爱你”、“www.saber.love”等。
但是我博客域名现在只用“saber.love”了,如何去掉这些已经不再需要的提示呢?其实这是有快捷键的,首先用键盘的方向键选中要删除的记录,然后按下快捷键来删除这条记录:
Windows:按 Shift + Delete
Mac:按 Shift + fn + Delete
Chromebook:按 Alt + Shift + Backspace
注意,下拉提示里的书签(前面显示为五角星图标)是不能这样删除的,还是去书签管理器中删除吧。
官方文档:《移除特定的联想查询》
先来两个在线的:
1.加加pdf
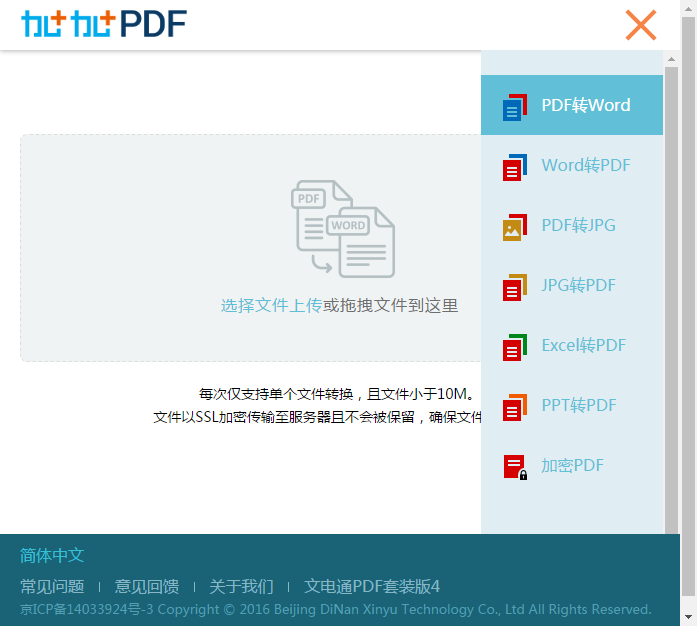
在线转换10M以下的pdf文件,免费。但是网页版不支持ocr识别。也就是说如果pdf文件里面是图片的话,转换之后依然是图片。
2.Smallpdf
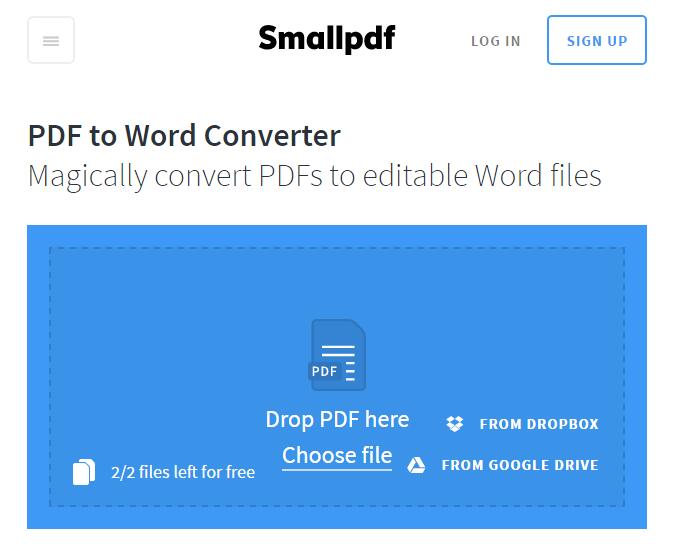
这个网站貌似不显示文件大小。它也没有ocr识别功能。另外这个网站虽然是国外网站,但依然能很好地识别中文。
其实上面两个工具的转换效果很接近。也都很不错。它们也都支持其他类型文件的互相转换。
Read More →
![(C91) [しもやけ堂 (逢魔刻壱)] 甘い純潔 第弐夜 (ガールズ&パンツァー) 百合本子 逢魔刻](/f/60585852_p0_master1200.jpg)
逢魔老师在c91上发售的百合本,全彩,画风自不必说,内容也很充实,值得收藏。
(C91) [しもやけ堂 (逢魔刻壱)] 甘い純潔 第弐夜 (ガールズ&パンツァー)
英文名:(C91) [Shimoyakedou (Ouma Tokiichi)] Amai Junketsu Dai Ni Ya (Girls und Panzer)
pixiv页面
ehentai页面
磁力链接:
(C91) [しもやけ堂 (逢魔刻壱)] 甘い純潔 第弐夜 (ガールズ&パンツァー).zip
(174M高清扫图,迅雷可离线)
更多预览:
Read More →
更新:蓝灯不好使了,别买了
去年就断断续续使用lantern了,它也并不完美,不过使用很方便。这个月我用的免费版的流量用完之后,买了两年的专业版。希望后续别坑爹。
我的邀请码是LF9THC。如果在购买lantern专业版时填入邀请码,在成功购买后,双方都将获得1个月(购买1年专业版)或三个月(购买2年专业版)的额外奖励时间。
在知乎上看到一个回答(知乎链接),是一个令人出离愤怒的刑事案件。在文章末尾,答主引用了一张图片,我觉得甚好。有些人就是心坏了,被抓后再扯那些有的没的,为自己的犯罪推脱责任,真是令人作呕。
图片太长,放到more里面了。
Read More →

之前本站域名统一301重定向到了"www.saber.love"。虽然大众的习惯似乎是在主站或PC站上使用www前缀,但是强迫症就很不爽了。www明明是个二级域名,但我实际上连一个二级站点都没有(可预见的未来也不会有),用二级域名完全没有意义。
好吧,其实上面是次要原因,主要原因是我感觉在saber.love这么好的组合前面加个www实在碍眼。于是就去掉咯~
ps:本文配图p站id=60899796,已经添加到了到了网站背景图里。

刚才看到一张阿福的礼装图,不知道是不是情人节的(我没玩日服,不太懂)。
果然可爱的男孩子赛高!
ps:没想到你是这样的
今天找了下出处,出自推特かんゆkun@Citron_82。
如果url中有特殊字符符号,可能会导致url不能被正确识别。
我们可以在传递参数前将url编码来解决这个问题。不过需要注意的是,有些字符在url中有独特的作用的(例如#表示锚点位置,&表示连接多个参数),所以JavaScript的encodeURI函数(意思是编码url)是不能编码这些有单独意义的字符的的。需要把它们也转码的话需要用encodeURIComponent函数(意思是编码url组件)。
下面直接列出一下有特殊含义的字符及其编码后的结果:
+ URL 中+号表示空格 %2B
空格 URL中的空格可以用+号或者编码 %20
/ 分隔目录和子目录 %2F
? 分隔实际的URL和参数 %3
% 指定特殊字符 %25
# 表示书签 %23
& URL 中指定的参数间的分隔符 %26
= URL 中指定参数的值 %3D
