


近来在学习 Vue.js,基础知识学的差不多了之后,想要做个项目融会贯通一下。这几天写了个博客前端,可以算是本站的一个皮肤(虽然丑)。这也是一个前后端分离的单页面应用。
在线访问:
数据和图片资源都是直接用的本站的。数据由 WordPress REST API 提供,不用自己写 API 接口了。
通过这个项目,进一步熟悉了 Vue.js 和它的相关插件,也学了学 muse-ui 和 Less 的使用,收获不小。
github 地址:
https://github.com/xuejianxianzun/vue-myblog-xjxz
好歹算是个展示吧,不指望有人用(用也用不好,因为我图片开了防盗链)。如果有人要用这个改一改,给 WordPress 后台的网站做个前台倒可以,毕竟后台的 API 一致,用起来方便。
效果预览:
Read More →

carnival.js 可以让网页不停地抖动,作者可真是个小机灵鬼。
在网站头部引用carnival.js:
<script src="https://nd002723.github.io/carnival/js/carnival.js"></script>
或者将下面代码保存为书签,动态引入:
javascript:void(function(){var d = document,a = 'setAttribute',s = d.createElement('script');s[a]('tyle','text/javascript');s[a]('src','https://nd002723.github.io/carnival/js/carnival.js');d.head.appendChild(s);})();
网站示例 (在这个页面点击书签部分的代码,稍等一会儿就能看到效果。)
本文由网友投稿
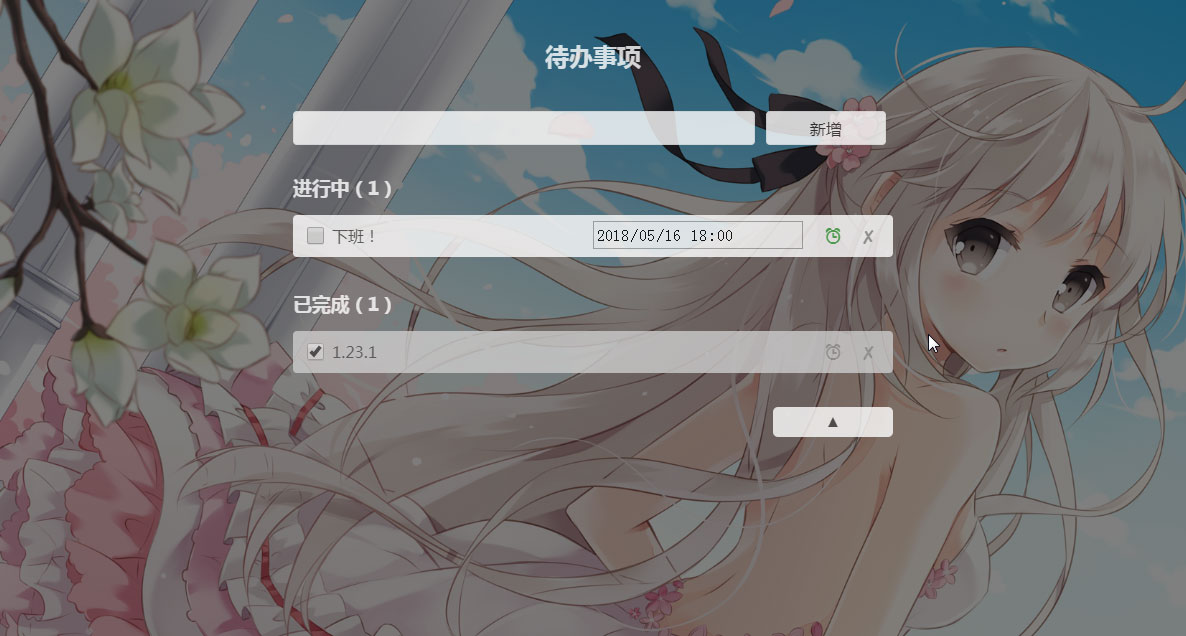
前些时候学习 Vue.js,做了个 todolist(待办事项),可以把自己要做的事情写上去做个备忘。大致效果如上。
这是一个简单的单页应用,你可以直接在线使用。
功能介绍:
您可以自由的添加、删除事项;切换完成状态;重命名;视需要设置定时提醒。
默认没有背景图片,因为用户可以自己设置背景图。(右下角设置区域)
默认有一个提醒铃声,用户也可以自行更改。
本页面会保存工作状态,关闭页面也不会丢失数据。 重新打开页面就可以继续使用了。
所有数据存储在用户本地,不收集用户信息。(话说我哪来的用户啊)
其他详见使用说明。(右下角设置区域)
Read More →

上图是截图,当然实际上樱花是会动的~
看了之前的下雪demo不由得手痒了起来,sakura啊,我需要sakura!然后果然在这里找到了一个,打开一看,好好看我喜欢呀~快F12扒下来吧,F12打开的一瞬间,我被密密麻麻闪烁变化着的div吓傻了,这样真的大丈夫?亚达哟,我要再找一个,结果找了半天不是不满意就是一个超级超级厉害的用似乎webgl做的,那算了,学webgl吧,看到摄像机啊什么的不由得想到了万恶的ae,自然摸鱼之心越来越膨胀,学着学着就来了一局昭和男儿的WT,等想起来学习webgl的时候,我就欺骗自己说,有unity3D谁还会用这鬼东西?算了算了,不学了,看我老婆(军神大人)去咯。。。。。。。emmmm,我的废话好多,言归正传,重而言之,我决定了改装下雪的demo,来场樱花雨吧,于是我就开始动起手来,先看看大概什么样子吧
代码比较长,这里就不贴出来了,从源代码里复制就行了~
ps:
此文章是投稿作品,欢迎大家投稿~(注册后可以在后台提交)
使用了基础的vue.js知识制作了这个邮箱提示效果~
LOFTER(乐乎) 是网易旗下的一款轻博客产品。很多人d到lofter就是为了看图,因为有些图片在这里有清晰的大图,而其他地方可能没有大图(比如很多cosplay图片,微博上的是小图,这里有大图)。
今天有人给我留言,说想要一个脚本,直接显示大图网址,方便下载。我看了下,lofter.com的图片没有加防盗链,可以直接下载,于是就做了这个功能。

安装地址:
https://greasyfork.org/zh-CN/scripts/39730
效果就是在图片列表上方显示大图的url,可以复制下来进行下载。
只在文章页有用哦~
之前我用的下雪特效是从b站扒的,依赖jQuery,并且对cpu资源占用略高。今天在某站看到了个更好的,不依赖jQuery,资源占用低,效果也更好。
demo:
代码如下:
Read More →
2015年的时候,我就发现UC浏览器不支持css的color: rgba属性值。不过这是旧怨了,最近我又发现一个问题。
如下代码:
<div id="a" style="margin-left: -100px;"></div>
<script>
// 使用js修改marginLeft的值
document.querySelector("#a").style.marginLeft = '-2rem';
</script>
用js代码将某个元素的css属性值重设,在其他浏览器上都正常,在UC上没反应。
元素是可以正确获取到的,但是设置css属性这部分就是不生效。
没办法,我只好改变思路,最后用其他办法实现了:
var a=document.querySelector("#a");
var str=a.getAttribute("style").replace("-100px","-2rem");
a.setAttribute("style", a);
直接重设style属性,这样可以。
珍爱生命,远离UC。
后面发生了一个更坑爹的事,同事的华为手机对rem计算不准确导致页面乱版,又废了好大功夫才弄好。今天下午大半时间都在折腾这页面了。
时至今日(2017年9月),用户体量庞大的新浪微博却仍然在使用http协议(默认情况下)。
据说近来新浪微博在测试https,具体表现为你在网址前面手动加上https:// 就可以使用https协议查看新浪微博。但手动的话比较麻烦,所以我写了这个用户脚本。
代码很简单:
if (window.location.protocol === "http:") {
window.location.href = window.location.href.replace("http", "https");
}
ps:我要吐槽一下微博这坑爹的http,我以前遇到过以下被坑的情形,都是手动切换到https就好了。
1.正常查看微博里的图片,打开速度非常慢。(经常)
2.打开我的相册界面,页面乱版以及无法上传图片;
3.忘了,待补
// ==UserScript==
// @name 百度贴吧自动顶帖
// @namespace https://saber.love/?p=3695
// @version 0.1
// @description 隔一段不定的时间,发表一条回复。不支持楼中楼。
// @author 雪见仙尊
// @match https://tieba.baidu.com/p/11111111111*
// @grant none
// @run-at document-end
// ==/UserScript==
/* 使用说明:
帖子网址需要通过修改脚本的match规则,手动指定。
如果需要修改发表内容,直接修改下面的“自顶”两个字即可。
默认的时间范围大概在0-500秒之间
*/
function setAutoPost() {
var timer = parseInt(Math.random() * 500 * 1000);
setTimeout(function() {
$("#ueditor_replace p").html("自顶");
$(".poster_submit").click();
setAutoPost();
}, timer);
}
setAutoPost();
百度贴吧自动顶帖,电脑版。使用帖子最下面的回复框来回帖,不支持楼中楼。
如果临时使用,只复制下半部分的JavaScript代码,在浏览器控制台手动执行也可以。
说明:
帖子网址需要通过修改脚本的match规则,手动指定。
如果需要修改发表内容,直接修改下面的“自顶”两个字即可。
默认的时间范围大概在0-500秒之间。
