


漫画(本子)的画面上有很多对话气泡,有些软件可以识别气泡里的文字并自动翻译和嵌字,所以即使你不懂日语,也可以自己翻译本子(生肉)。当然,这是机翻,不过也可以搭配 AI 翻译,效果也算不错。
本文介绍的软件 BallonsTranslator 就是这样的软件。它是大佬用 Python 开发的开源软件,主页地址:
https://github.com/dmMaze/BallonsTranslator
我会简单做个使用介绍,看了这篇文章,你也能自己翻译本子啦!
首先你应该有梯子(翻墙软件),开启全局代理,也就是修改了系统的代理服务器。然后打开网盘链接 MEGA 或 Google Drive,下载 BallonsTranslator_dev_src_with_gitpython.7z 并解压。
解压后的文件夹名字可能是 BallonsTranslator_dev_src_with_gitpython,我们可以将其重命名,简化为 BallonsTranslator。
进入文件夹,运行 scripts/local_gitpull.bat 来更新代码。(可选,这一步需要先安装有 git,你没有的话可以跳过)
执行完毕后再回到上层目录,运行 launch_win.bat 启动程序(如果出错,可能需要你先安装 Python 并将其添加到 PATH,也就是环境变量里)。第一次启动时,它会下载很多文件和安装一些包,整个过程都是自动的。具体花费的时间和你的下载速度挂钩。
有时候它可能会看起来像卡住不动了,但实际上还在运行,可以多等一会儿。等待其运行完毕,就会自动打开程序。
程序界面如下:
左边的侧边栏从上到下可以切换到不同的视图/工具,依次是:
要处理的图片统一放到一个文件夹里作为项目文件夹,不要和无关图片混杂。我截了几张图作为测试图片:

在 BallonsTranslator 里打开这个文件夹,它会自动定位到第一张图片。在文件列表里可以切换不同的图片。
它不会立即翻译。如果想只翻译这一页,可以点击软件底部的“翻译本页”按钮。如果要批量处理则可以点击 Run 按钮。在“运行”菜单里也有这两个功能。
批量处理时,在软件右下角会显示进度条,处理之后会在图片文件夹里生成子文件夹来保存结果:


inpainted 文件夹里保存的是把文字抹掉,留下空白气泡的图像。

可以看到它对于底部的方形文字块也进行了处理,不过文字抹除的不够干净。白色气泡就很简单了,处理的没问题。
mask 文件夹里保存的是日语原文字的遮罩,是黑白的:

result 文件夹里保存的是将日文替换为中文的结果。软件会根据日语原文的字号来自动设置中文的字号。横排竖排的处理也是自动的。多数时候的效果是还可以的。

点击文字区域,可以在右侧修改字体样式和文字内容(这点以后再详细说明下):
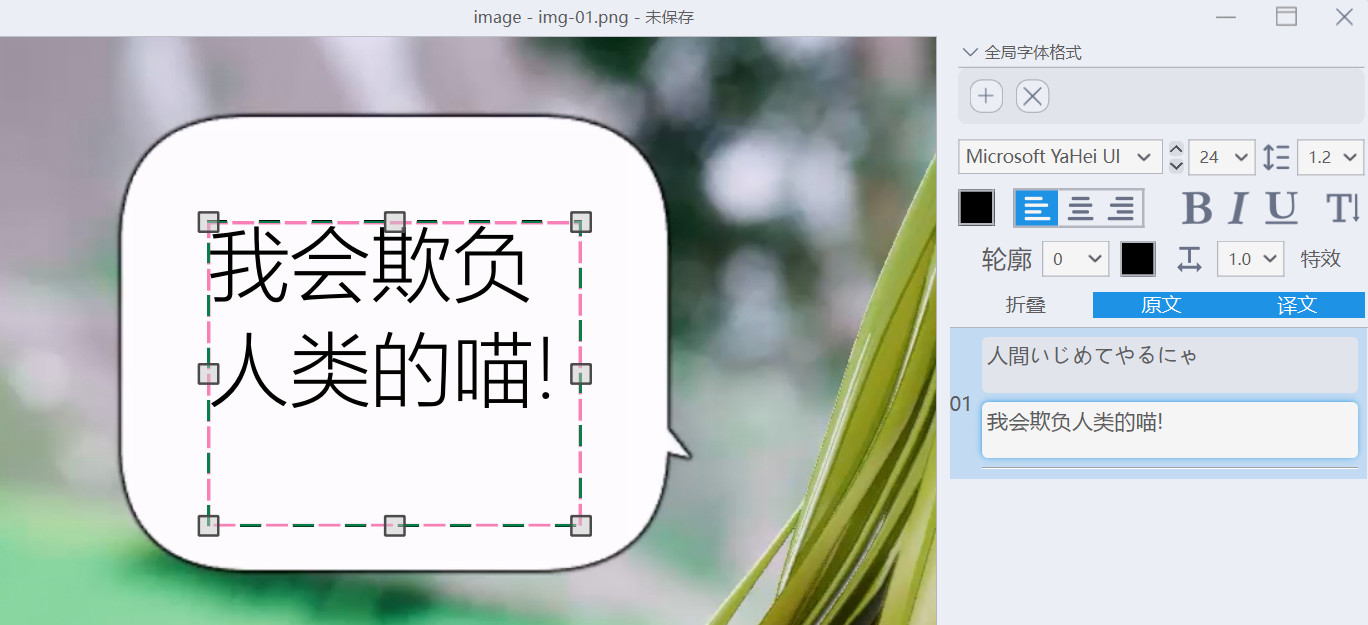
修改之后按 Ctrl + S 进行保存,result 文件夹里保存的结果图片会自动更新。
有一个按钮用于把文字变成竖排:
另外,在视图菜单里可以切换显示右侧的面板,除了文字面板,还有个简单的修复面板,主要是用来涂抹一些没自动处理好的地方:
在选择文字框时,按 Ctrl + A 可以全选。按 Ctrl 同时鼠标点击,可以进行多选。
在文本框上右键还有右键菜单,不过我没怎么用到。
如果图片显示的太大了,可以用 Ctrl + 鼠标滚轮调整缩放。
BallonsTranslator 的默认字体是微软雅黑。我们可以设置一个或多个全局字体,这样可以让它在批量处理时应用,而且我们手动修改时也会更快捷。
在文字编辑区域点击加号,就可以把当前字体样式保存为一个全局样式。
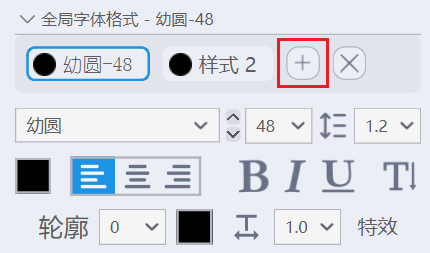
之后在设置里将字体大小从“由程序设置”改为“使用全局预设”:
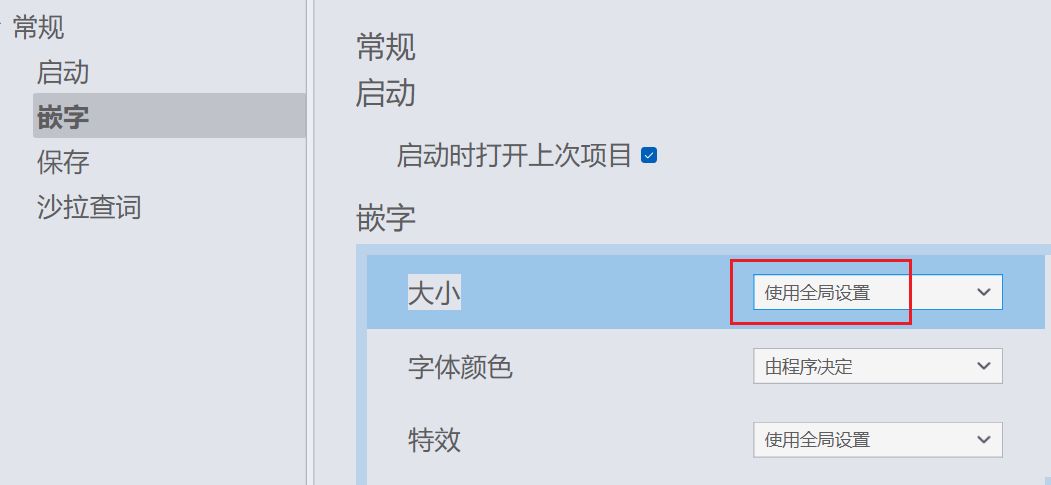
之后再运行一遍 Run(批量处理),所有文字都会被应用你选择的样式。
在有多个全局样式时,选中哪个,批量处理时就会使用哪个。
设置一个合适的全局样式可以节约很多时间,之后我们只需要修改文字内容和换行,不会在调整样式上浪费太多时间。
另外还有个小技巧,如果一个页面上所有文字都需要调整大小,可以按 Ctrl + A 全选,然后调整右侧的字号,就可以全部修改了。
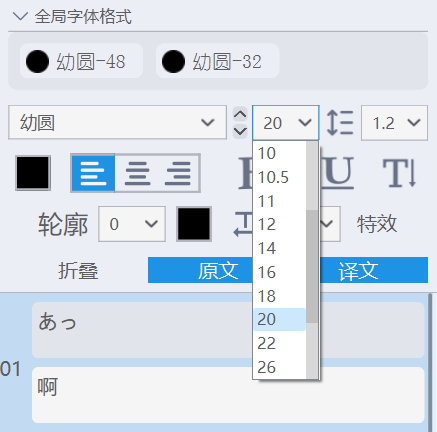
有时手动修改字号之后后,生成的图片里有些文字大小不对。其实对于一个文本框来说,鼠标单击选中它时,右侧的字号是全局样式的大小。双击进入编辑模式时,字号才是实际的大小。反正有时候搞得我也有点混乱。出现文字大小异常的解决办法就是双击进去重新设置一次字号。
BallonsTranslator 默认的翻译引擎是谷歌翻译,效果不好。虽然可以在设置里选择其他翻译器,但是多数效果都不好,需要我们花费大量的精力去核对和修改。
点击打开文件夹的按钮,有个功能是导出为 word 文档,它会导出所有图片的原文区域(图片)和翻译结果(文字):

这在需要把原文发给翻译人员进行处理时应该很有用。
它也可以选择使用 ChatGPT 翻译,但是 ChatGPT 是需要 api key 的:
如果你已经有了 api key,那很方便,但是我发现要获取 api key 还是挺麻烦的。
首先在 OpenAI 官网注册个账号:
https://beta.openai.com/signup
然后打开获取 api key 的页面:
https://beta.openai.com/account/api-keys
这里的难点在于要验证手机号:
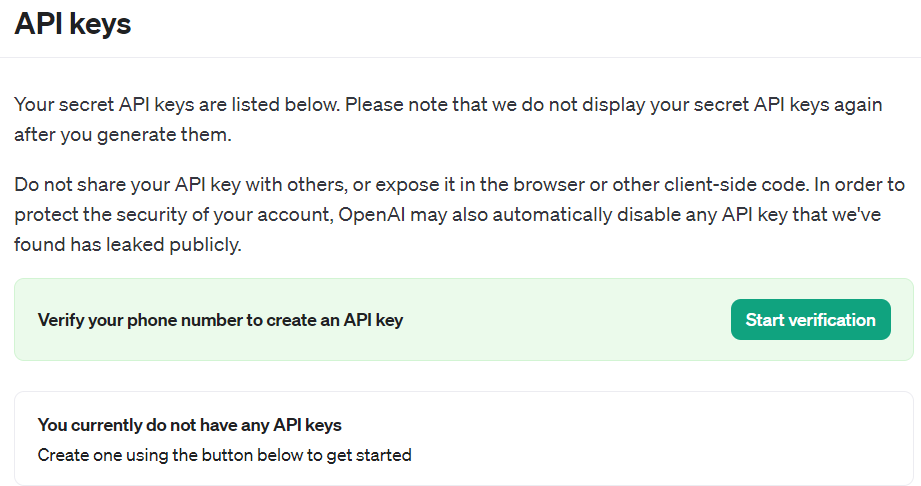
大陆的手机号是不能用的,因为 OpenAI 不在大陆提供服务。一些虚拟手机号也不行,会被它识破。我找到了个类似于租号平台的网站,看起来可以花钱用真实的手机号接收验证码,但是它最低充值 2 美元。我搜索看到有人说这种不可靠,可能充了钱也收不到码,或者一个号码被使用太多次,会被 OpenAI 识别为滥用,也就无法做验证了。
另外即使验证了手机号,使用 api key 也是要付费的。具体价格算不算贵嘛,我没用过不好说。
有人告诉我可以在其他网站买 ChatGPT 会员用,比官网的便宜,也不需要我们头疼验证手机号的问题了。不过有的可能不稳定,因为很多是黑卡,可能个把月左右被查出来就会被封。我现在还没试。另外用 API 的话,不要用大陆和香港 IP,因为这些地区是不能使用 OpenAI 的。也不要调用的太频繁,在设置里可以设置间隔时间。
教程到这里就算结束了,你学废了吗?我刚才随便找了张本子图翻译一下试试:

看起来还挺像回事的嘛~不过幼圆字体的标点符号与文字挨的太近了,可以考虑换个字体。
下面的内容是我瞎折腾的,不算教程的一部分。想看的话就随便看看吧。
我想提取日语原文,然后用我已经购买了会员的 Fusion 机器人来翻译。那么如何获取日语原文呢?
导出的 word 对我没用,因为我不懂日语,我想把软件识别到的日语以文字形式导出,方便让 AI 去翻译。
在项目文件夹里有个文件 imgtrans_image.json,里面有原文数据,可以从这个文件里提取:

文字数据保存在 pages 对象里,key 是每个图片的文件名,value 是一个数组,保存这个图像的数据,每条文字的数据是一个子对象。
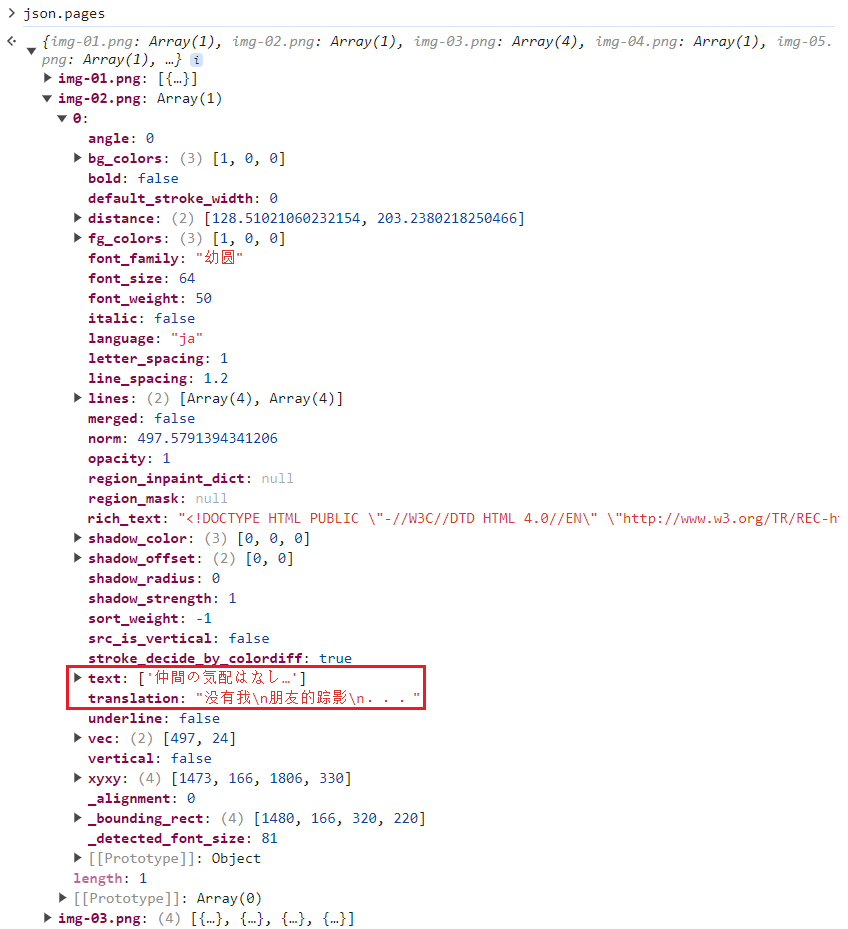
子对象的 text 属性保存着原文。所以读取一条原文的路径是这样的:
json.paegs["img-01.png"][0].text[0]写一个函数来提取文本:
function extract (json) {
const result = []
for (const [key, value] of Object.entries(json.pages)) {
const r = {}
r.name = key
r.data = []
for (const textData of json.pages[key]) {
r.data.push({
text: textData.text[0],
trans: textData.translation
})
}
result.push(r)
}
console.log(result)
}输出格式如:

接下来可以直接用这个 JSON 让 AI 翻译,也可以再写一个函数,输出纯文本去翻译。我写了个函数输出纯文本内容:
function exportOriginText (result, firstFileNo) {
const text = []
for (const item of result) {
text.push(firstFileNo)
firstFileNo++
for (const array of Object.values(item.data)) {
text.push(array.text)
}
text.push('\n')
}
console.log(text.join('\n'))
}输出入:
1
人間いじめてやるにゃ
2
仲間の気配はなし…
3
🍬…I
村の人たちを困らせてるあなたね?
ンニ
退治してくれって頼まれたんだけど
4
人間と仲良くしてくれないかなぁ?糖果表情是 BallonsTranslator 误把一些非文字内容识别为文字导致的。以后在软件里手动删掉这个地方的文字就行了。
用这样的纯文本丢给 AI 翻译:
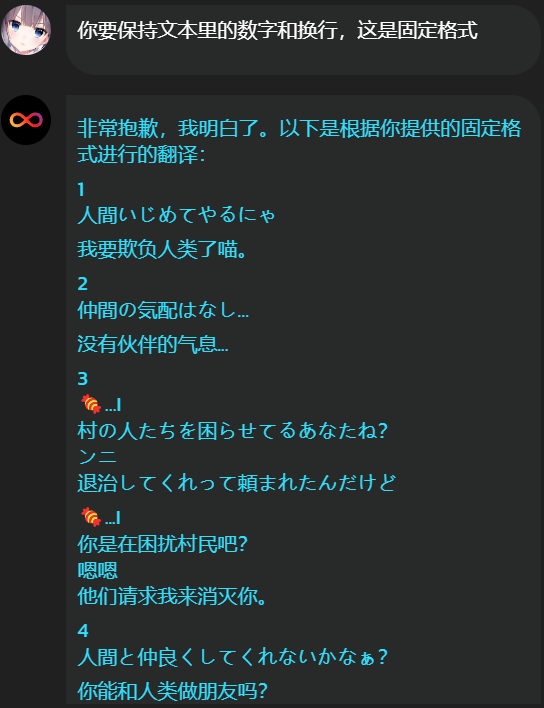
但是它对格式理解错误,而且出于另一个原因(后面会说),最后我还是让 AI 去直接翻译 JSON 格式了。
对比一下翻译效果,不用说 AI 肯定是爆杀谷歌机翻:(上方是谷歌翻译,下方是 AI 翻译)
我会欺负人类
我要欺负人类了喵。
没有我朋友的踪影...
没有伙伴的气息...
你给村民们添麻烦了是不是?
你正在困扰村民对吧?
我被要求摆脱它。
他们请求我来消灭你。
我不知道你能和人类和平相处吗?
你能和人类做朋友吗?在翻译完成后,还有一个问题,那就是怎样把翻译后的文字应用到软件里?笨方法是一条一条复制粘贴,手动替换。但是在文本量大的时候太费时间了。
另一个思路是修改导出的那个 word 文档,因为它本来就是让翻译去校对文字的,我们把翻译结果替换到 word 文档里,然后导入 word 文档。但是这样还是要一条条手动复制。
还有个办法,既然我们的日语原文是从项目文件 imgtrans_image.json 里提取的,那就直接对它进行改写。这样效果最直接,而且也可以用编程的方式快速处理。如果用这个方法,那么用来回写(输入)的数据最好也是 JSON 的,这样方便编程。
所以我让 AI 去翻译之前输出的 JSON,结果符合预期:
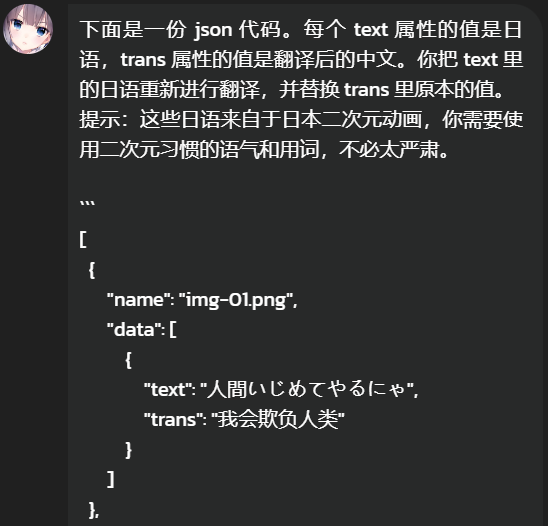
我的提示是:下面是一份 json 代码。每个 text 属性的值是日语,trans 属性的值是翻译后的中文。你把 text 里的日语重新进行翻译,并替换 trans 里原本的值。
提示:这些日语来自于日本二次元动画,你需要使用二次元习惯的语气和用词,不必太严肃。
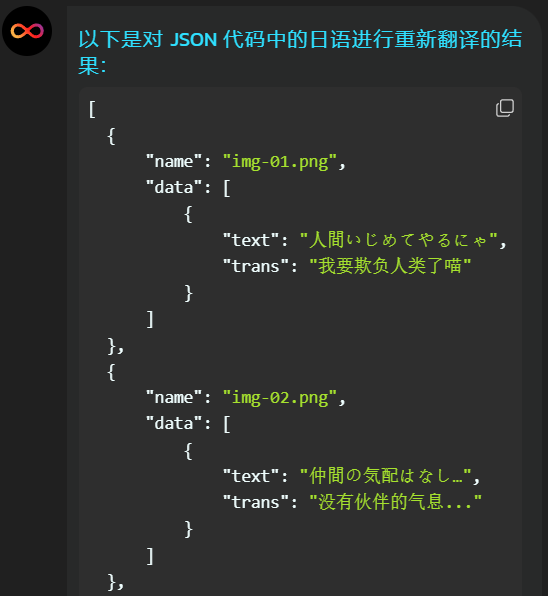
之后需要再写一份代码,用 AI 翻译的中文替换 imgtrans_image.json 里的中文。
首先关闭软件,并备份 imgtrans_image.json。写个函数将 AI 翻译的结果进行回填:
function rewrite () {
for (const item of input) {
const pages = target.pages[item.name]
for (let i = 0; i < item.data.length; i++) {
// 修改 translation 的值
pages[i].translation = item.data[i].trans
// 还需要修改 rich_text 里的值,这才是显示在图片上的文字
// 由于源文件里一句话可能会有多个换行,这会产生多个 p 标签。但是我提取和翻译的文字没有换行,不能原样处理
// 所以这里只好将其替换为一个不换行的样式,只有一个 p 标签
pages[i].rich_text = `<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.0//EN\" \"http://www.w3.org/TR/REC-html40/strict.dtd\"><html><head><meta name=\"qrichtext\" content=\"1\" /><meta charset=\"utf-8\" /><style type=\"text/css\">\np, li { white-space: pre-wrap; }\nhr { height: 1px; border-width: 0; }\nli.unchecked::marker { content: \"\\2610\"; }\nli.checked::marker { content: \"\\2612\"; }\n</style></head><body style=\" font-family:'幼圆'; font-size:48pt; font-weight:400; font-style:normal;\"><p style=\" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\"><span style=\" font-weight:50; color:#000000;\">${item.data[i].trans}</span></p></body></html>`
}
}
console.log(target)
}
rewrite()运行之后,将输出的 JSON 内容粘贴到 imgtrans_image.json 里,覆盖原本的内容,保存后重新打开 BallonsTranslator。可以看到图片上的文字已经变成 AI 翻译后的了:
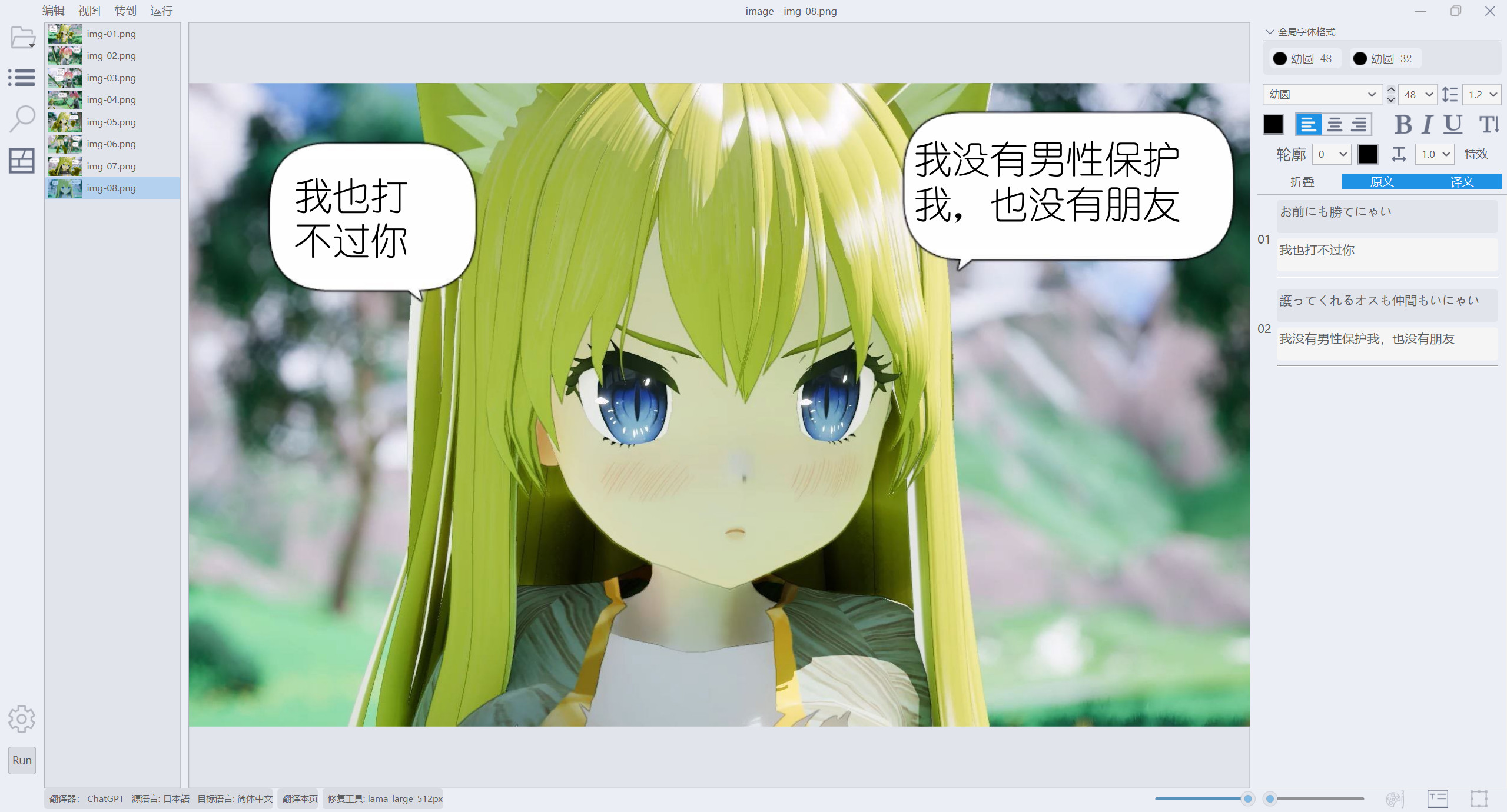
话说,之前谷歌很离谱的将左边的“我也打不过你”翻译成了“我也能打过你”,意思完全反了。其实紧接着后面还有一句话,只是截图只截到这里,没截后一句话:
ウ子は終わりにゃ!煮るなリ焼くなリ好きにしにゃ!
现在已经结束了!无论是煮还是烤,都随便你!(猫猫说话也太可爱了)从这句话来看,猫娘显然是承认自己的败北,那么前一句应该说“反正我也打不过你”。AI 在没有后一句的情况下正确的完成了翻译,斯国一内~
但是现在遇到一个问题,那就是这种直接修改 imgtrans_image.json 的方式,软件无法检测到图像被修改了,此时按 Ctrl + S 也不会保存,也就无法生成图片文件。
解决办法是在“运行”菜单中取消选中所有功能:

然后再运行也就是进行批量处理,这样没有进度条,但是会生成 result 图片。
更偷懒一点想,为什么不直接让 AI 翻译 imgtrans_image.json 本身呢?这是可以实现的,但是一个现实的问题是,AI 每次能接收的输入字符是有限的。保存了 8 张图片数据的 imgtrans_image.json 有 27 KB,不能一次发给 AI,需要拆分多次。而我提取后的 JSON 文件是 2 KB,体积不到它的十分之一,不需要拆分。即使以后数据变多了需要拆分,操作次数也会少很多。
忙活半天,看来最佳的办法还是用 ChatGPT 的 key 直接翻译,这样省了提取数据再导入数据的麻烦。
这个软件适合翻译漫画,但是我其实是想翻译视频的。其实上面的截图就是出自一个视频,它的时长超过半小时,30 FPS,合计 69172 帧。视频画面是动态的,不是 PPT,但是对话气泡是固定位置的。如果视频是纯静态图的 PPT,那就和翻译本子一样,没任何难度了。
虽然我搜到了一些剪辑软件能自动将视频里的文字翻译,并生成新视频,但它们都是收费的,也不知道是否支持日译中。这种剪辑软件我看都是用来剪辑竖屏的短视频,感觉不太适合我要翻译的这个视频。何况我这个视频还有成人内容,呃呃。
如果大家有免费的翻译日文视频的办法(只翻译文字,而不是翻译语音或做字幕),并能实现嵌字效果(就是把对话气泡里的日文抹掉,打上中文),欢迎告诉我。
我原计划是把视频里带对话的画面都截图保存,然后翻译,最后回填。但实际上每个环节都存在难题。
截图,一个省人力的办法是每帧都生成一张图片(可以用 FFmpeg 自动操作),然后所有图片都用这个软件批量翻译,然后我再用 AI 优化翻译。也就是重复本文里的操作流程,得到翻译和嵌字之后的图片。最后再用所有图片来合成一个视频。但是 69172 帧似乎有点多。那么如果我只截取有对话的画面(相同对话只截一张),可能只要几百张图片。但是这样没法用这几百张图片合成完整的视频。
翻译,最省事的办法就是用 ChatGPT 的 API 翻译(假设用 API 的方式不会审查成人内容)。只需要花些钱,以及克服验证手机号的问题,就能省很多时间,不用像本文里一样又要写代码、又要用聊天机器人翻译这些曲折的操作了。
合成。如果是每一帧都截图的话,是最省事的。如果只截取几百张有对话的图,那么就没法直接合成视频了,需要用视频编辑器打开原视频,再把翻译后的图片的气泡部分叠在原视频画面上。这需要定位和调整许多时间轴,在视频编辑器里操作几百张图片,而且还要扣气泡。(因为原视频画面是运动的,而截图是静态的,所以只能取气泡部分盖在原视频上。不能直接把整张图都盖在原视频上,那就成 PPT 了。)
额,折腾了数个小时,最后我觉得,天下无难事,只要肯放弃!晚安,玛卡巴卡!
 Firefox 114
Firefox 114 Android 10
Android 10  Google Chrome 123
Google Chrome 123 Windows 10/11
Windows 10/11 不清楚,我没试过
Google Chrome 115Windows 10/11 呃 抱歉看错了
视频是漫画形式的......
这就离谱了。。。
? 可以一边看截图翻译的漫画 一边听声音也行?哈哈哈哈
Google Chrome 115Windows 10/11 字幕提取器下载地址:https://github.com/YaoFANGUK/video-subtitle-extractor
https://bbs.acgrip.com/forum.php?mod=viewthread&tid=7385&highlight=%E7%A1%AC%E5%AD%97%E5%B9%95%E6%8F%90%E5%8F%96
这2个都可以提取视频里的字幕
可以提取视频里的字幕成srt文件
然后我的方法是 写2个脚本 一个是拆分 SRT格式成时间轴和独立的文本
然后拿文本去翻译 翻译完再写一个脚本 合并翻译完的文本和时间轴
成一个新的翻译完的sRT文件 如果想要对着
还可以再写一个脚本 合并最开始的原文和翻译完的SRT成一个双语字幕文件
https://picshack.net/ib/E9KiKJ9juX.png
还有字幕消除器
https://github.com/YaoFANGUK/video-subtitle-remover/releases/tag/1.1.0
可以却掉视频里的水印和文字
Google Chrome 120Windows 10/11 ok 硬字幕提取这个我以前也用过,挺简单好用的
Google Chrome 115Windows 10/11 哈哈 大佬
这个 不会是您吧?
https://github.com/dmMaze/BallonsTranslator/issues/347
刚才刚回答 类似的问题
Google Chrome 120Windows 10/11 是我,被你逮了个正着
Google Chrome 115Windows 10/11 因为回答问题的就是我哈哈哈哈
Google Chrome 120Windows 10/11 抱住大腿

{kind=link}
GPT的apikey直接输入就完成了吗?我看下面还有空的选项