


在浏览器中,如果 POST 请求的 body 数据是 FormData 类型,那么浏览器会自动把数据以 multipart/form-data 格式编码并发送,不需要我们进行额外处理。
const formElement = document.querySelector('#form')
const formData = new FormData(formElement)
fetch('/post', {
method: 'post',
body: formData,
})multipart/form-data 编码方式可以用于上传文件。不过即使不上传文件,因为 FormData 用起来很便捷,所以我也习惯使用它。
但是极少数情况可能需要我们自己把表单数据编码成 multipart/form-data 格式,于是我就尝试了一番。
演示页面: encode-form-data.html
我做好之后上传了上来,你可以点击杀昂面的网页查看示例及源码。(这个网页没有对应的后端,所以发送的请求会失败,不过依然可以在 network 里查看编码后的数据)
代码其实很少,但是折腾和试错的过程花了挺多时间的。
服务端有个 API 只能接收 multipart/form-data 类型的数据。之前只有一个普通网页(在浏览器中)会请求这个 API,由于浏览器会自动编码数据,所以无序我手动处理。但现在我需要在微信小程序里使用这个接口,但是根据微信小程序的文档:
它里面说会把数据转换成 String,但是没有提及需要提交 multipart/form-data 格式的数据时会如何处理。
小程序不能自动把 FormData 类型的数据编码成 multipart/form-data 格式的字符串,所以我需要自行把表单里的数据转换成 multipart/form-data 编码。
我参考了这篇文章:https://www.jianshu.com/p/e810d1799384
在发送 multipart/form-data 数据时,我们必须设置请求头的 content-type 为 multipart/form-data; boundary=<分界线>。
boundary 是客户端可以自行定义的分界线(但是不要太短,以避免数据正文里包含了分界线字符,造成错误)。
假如我设置如下请求头:(分界线为 xuejianxianzun)
content-type: multipart/form-data; boundary=xuejianxianzun假如我要发送两条数据,一条是纯文本,一条是上传的文件,那么编码后的格式如下:
--xuejianxianzun
Content-Disposition: form-data; name="youname"
雪见
--xuejianxianzun
Content-Disposition: form-data; name="file1"; filename="saber.mp4"
Content-Type: video/mp4
<二进制数据>
--xuejianxianzun--每条数据以 --分界线 开头;下一个 --分界线 则是下一条数据的开头。
最后的 --分界线-- 是全部数据的终止符,表示内容已结束,只会出现一次。
对于纯文本值的字段,格式如下:
--<分界线>
Content-Disposition: form-data; name="<字段名>"
字段值对于文件类型数据,格式如下:
--<分界线>
Content-Disposition: form-data; name="<字段名>"; filename="<文件名>"
Content-Type: <文件的MIMEType>
<二进制数据>如果有多条数据,就按格式把它们依次排列起来,最后加上终止符 --分界线-- 就可以了。
必须严格遵守换行的要求。
\r\n 而不能使用 \n。否则数据无法被后端解读,例如我所使用的库会报错 Unexpected end of form。\r\n;但是每条数据的中间有个空一行的地方,那里需要连续 2 个换行符,不能偷懒只用 1 个。此外每个分号、空格都不能省略,必须严格按照规则进行编码。
当没有 input[type="file"] 时,所有值都是基本类型(String、Number、Boolean),直接按照编码格式拼接出字符串,然后作为 POST 请求的 body 发送即可。
提示:multipart/form-data 编码会把基础值都转换成字符串,所以你会丢失 Number、Boolean 类型(如果需要的话可以在后端转回来)。
可以参考以下代码:
const boundary = 'qingdaoweixinxiaochengxu'
const data = {
"formID": "1",
"time": '2023-04-20',
"name": '小程序',
"sex": "",
"phone": '123456789',
"office": "1",
"content": '123'
}
const str = this.encodeFormData(data, boundary)
console.log(str)
fetch('http://localhost:8001/postform', {
method: 'post',
headers: {
'Content-Type': `multipart/form-data; boundary=${boundary}`,
},
body: str,
})
function encodeFormData (data, boundary) {
const tempArray = []
for (const key of Object.keys(data)) {
const string = `--${boundary}\r\nContent-Disposition: form-data; name="${key}"\r\n\r\n${data[key]}\r\n`
tempArray.push(string)
}
tempArray.push(`--${boundary}--`)
return tempArray.join('')
}不过纯用字符串拼接无法处理上传文件的需求,所以我使用了下面的编码方式。
这就麻烦些了,因为编码规范里有纯文本字符,但是文件却要用二进制数据,那么字符串和二进制数据怎么拼接成为一个整体呢?
没法拼接,只有一个办法,就是把纯文本和文件数据全都转换成二进制数据,发送的不再是字符串而是二进制数据。
这里说的二进制数据是 ArrayBuff 容器保存的数值,数据格式为 Uint8Array。
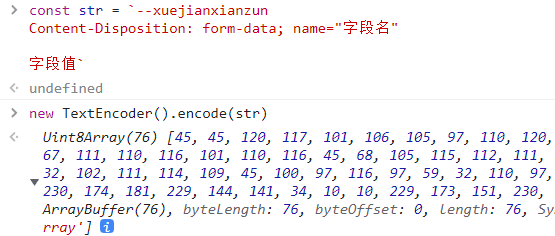
字符串怎么转换成 ArrayBuff 呢?用 TextEncoder,如下示例:
const str = `--xuejianxianzun
Content-Disposition: form-data; name="字段名"
字段值`
const encoder = new TextEncoder()
encoder.encode(str)这样可以把字符以 UTF-8 格式解读,并编码为 Uint8Array。
文件怎么转换成 ArrayBuff 呢?input 控件的文件数据是 File 或 Blob 类型,自带 arrayBuffer 方法:
const file = form.file1.files[0]
const fileBuffer = await file.arrayBuffer()
const fileUint8Array = new Uint8Array(fileBuffer)由于 ArrayBuff 不能像字符串一样直接拼接,也不能像数组一样直接合并,所以我们需要创建一个数组,保存编码过程中产生的多个 ArrayBuff 片段,最后再合并起来。
// 保存拼接数据过程中各个部分的 Uint8Array
const tempArray = []
// 编码过程中
tempArray.push(编码后的字符串)
tempArray.push(编码后的文件)
tempArray.push(编码后的字符串)
// more...
// 统计所有 Uint8Array 的总长度
let totalLength = 0
for (const uint8Array of tempArray) {
totalLength = totalLength + uint8Array.byteLength
}
// 构建一个新的 Uint8Array 拼接所有数据
const AllUint8Array = new Uint8Array(totalLength)
let offset = 0
for (const uint8Array of tempArray) {
AllUint8Array.set(uint8Array, offset)
offset = offset + uint8Array.byteLength
}
// 编码完毕,返回数据
return AllUint8Array不管数据是编码成纯文本还是 ArrayBuff,在发送时都是一样的:
fetch('/testformdata', {
method: 'post',
body: encodedData,
headers: {
'content-type': `multipart/form-data; boundary=${boundary}`,
},
})除了 fetch,你也可以使用 XHR 发送数据。
由于我们是手动编码数据,所以需要手动设置 content-type 的值。
另外,有些教程在发送数据时会手动设置 Content-Length 的值,但是在浏览器中不必设置,因为浏览器会自行设置 Content-Length,而且我们自己设置的 Content-Length 值是不会生效的。
如果你有必要设置 Content-Length,那么它的值是所有数据(Uint8Array)的 byteLength(字节数)。
byteLength 是 ArrayBuff 或者 Uint8Array 等类型化数组的一个属性,也就是字节数,或内存使用量。
注意:字符的 length 不一定等于它们转换成二进制后的 byteLength。比如 UTF-8 里一个汉字占据 3 个字节的内存。
const str = '雪见'
// str.length 是 2
new TextEncoder().encode(str)
// 生成 6 字节的 Uint8Array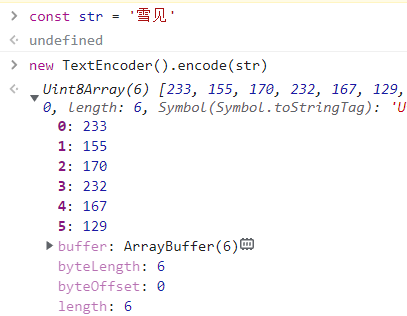
我制作的测试页面里有 3 个基础类型的 input,还有两个文件选择 input(可以随意选择不同类型的文件)。点击提交按钮将表单数据通过自定义的编码函数处理,最后发送出去。
发出请求后,在开发者工具的 network 里查看载荷,应该看到所有字段的值都符合预期:
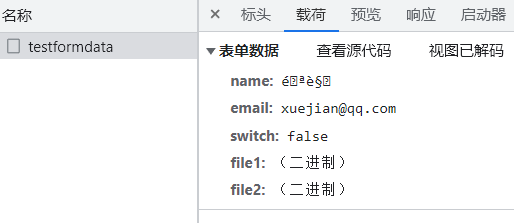
文件的类型应该显示为二进制(或 binary)。
在后端输出解析后的数据,可以看到纯文本值(被解析为对象键值对),以及文件数据:
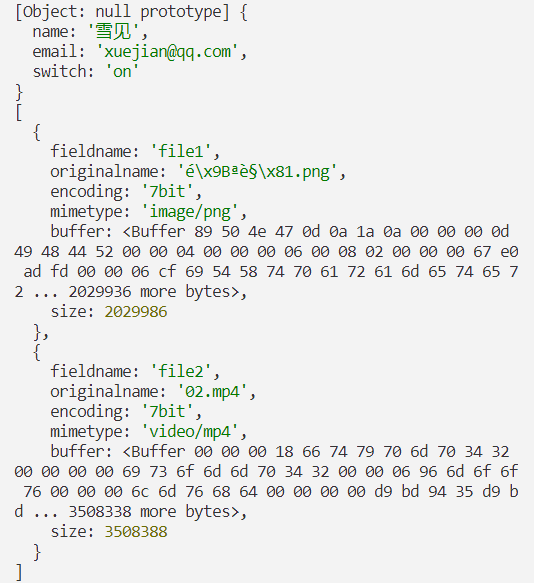
将文件保存到指定文件夹中,文件的大小应该和源文件一致,并且是可以正常打开(而非损坏的)的文件。
这样手动编码就成功了。
不过在 network 里查看载荷时,手动编码和浏览器自动编码所显示的内容稍有区别。(只是显示有区别,对于后端来说解析出的结果是一样的)
区别 1:手动编码后,基础值里的中文如 雪见 显示为乱码,浏览器编码的不会显示为乱码:
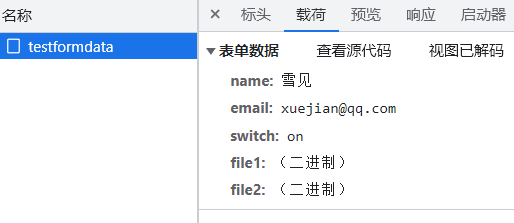
不过这样看上去乱码的基础值,在后端解析时没有影响,都是能够解析成中文的。
区别 2:虽然文件的内容都会显示为“二进制”,但是点击“查看源代码”时,手动编码的会显示文件内容:
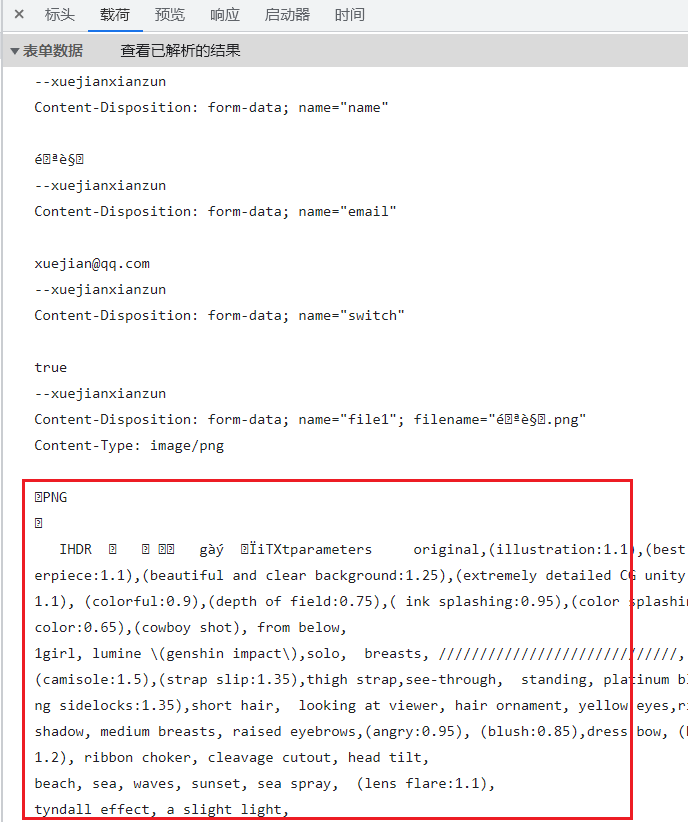
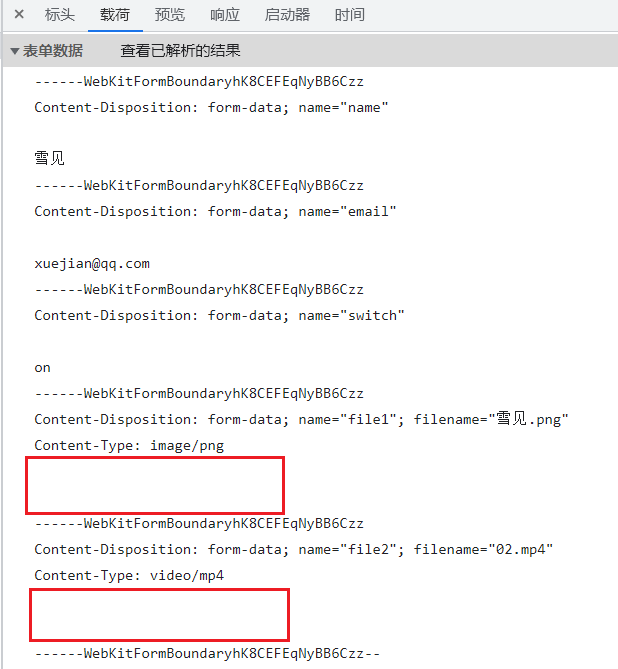
但是浏览器编码的不会显示文件内容(只是看起来好像多了一个空行,代表这里是二进制数据)。
前面已经提到过,有些文字不像英文字母一样仅占据一个字节。
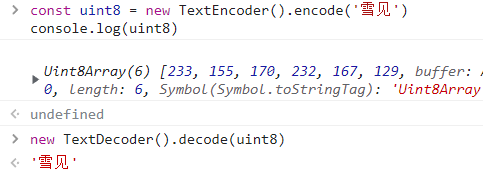
雪见 被编码为 6 个字节 [233, 155, 170, 232, 167, 129],并且之后还可以把它解码回去。
其他一些文字如日语、emoji 表情等也要使用多个字节来表示。
但如果每个字节会被分别解读,那么我们就会看到 雪见 变成了 6 个乱码的字符:
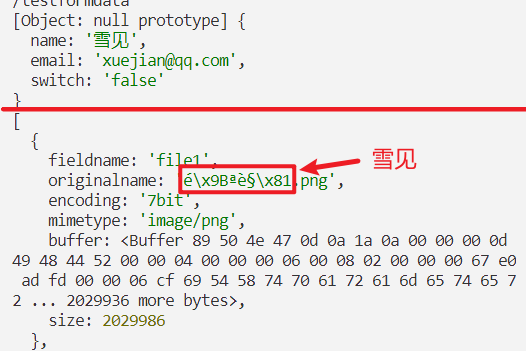
后端接收到的文件数据里,文件名的 雪见 输出为 é\x9Bªè§\x81(在浏览器里的 network 里可能显示为 éªè§,其实是一样的,只不过第 2 和第 6 个字符在终端里显示为 16 进制的值,在浏览器里显示为未知符号 )。
如果把这样的乱码字符用作为文件名,那么文件保存后的名字也是乱码。
ps:图中上半部分是纯文本的值,中文解析正常,不用额外处理。
ps:这个问题并不是手动编码存在问题导致的;浏览器自动编码的数据也同样如此。
小小探究一下原因,我建立了个 txt 文档,内容为 雪见,用 16 进制查看器打开查看:
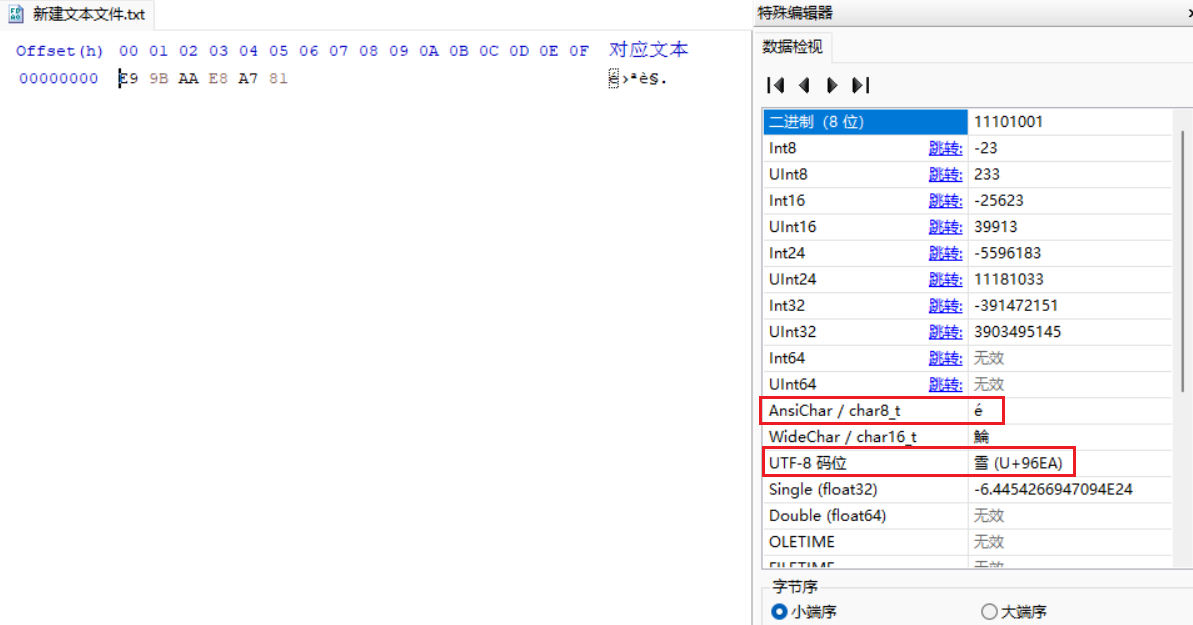
显然,有时软件没把字符正确解析。JS 引擎把这 6 个数字逐个转换为了 UTF-8 编码的字符,得到了 6 个乱码字符 é\x9Bªè§\x81。
从表现上来看,它转换成的字符和 AnsiChar 或 chra8_t 一致,这是因为 1 个字节的无符号整数的值是 0 -255,其范围和对应的文字与 ANSI 编码相同。
ANSI 字符列表:https://en.wikipedia.org/wiki/Windows-1252#Codepage_layout
那么在后端怎么把它还原成 雪见 ?
我首先尝试把 é\x9Bªè§\x81 编码再解码:
`é\x9Bªè§\x81`.length
// 6 个字符
new TextEncoder().encode(`é\x9Bªè§\x81`)
// 12 个字节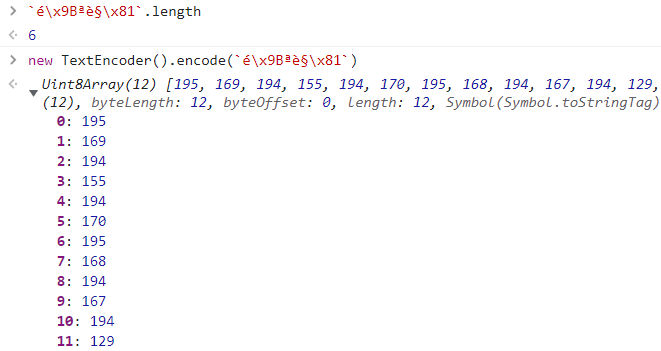
此路不通,因为原本 雪见 是 6 字节,但把 é\x9Bªè§\x81 编码后可以看到它现在是 12 个字节,每个字符用 2 个字节储存。
为什么会这样呢?因为 JS 引擎把每个数值都转换成了 UTF-8 字符供我们使用。在 UTF-8 的规范里,128 - 255 的数字会被解析为占据 2 个字节的字符。所以 雪 的第一个字节 233 解析成了占据 2 个字节的字符 é 之后,内存占用翻倍了。
(由于 0 - 127 在 UTF-8 里只占用 1 个字节,所以英文字符在后台解析出来后依然只占据 1 个字节,不会像中文这样翻倍)。
那怎么从 é\x9Bªè§\x81 里获取到 6 个原始值(数字)呢?
答案是对每个乱码字符用 charCodeAt 取值,charCodeAt 每次处理一个字符,获取它的 16 进制数值,所以可以得到 6 个值,这正是 雪见 的 6 个字节的原始值。
最后就可以用 TextDecoder 解码出原文了。
const errorStr = `é\x9Bªè§\x81`
const uint8Array = new Uint8Array(errorStr.length)
for (let i = 0; i < errorStr.length; i++) {
uint8Array[i] = errorStr.charCodeAt(i)
}
console.log(uint8Array)
// 得到 `雪见` 原本的 6 个字节的数值
const name = new TextDecoder().decode(uint8Array)
console.log(name)
// 还原出 `雪见`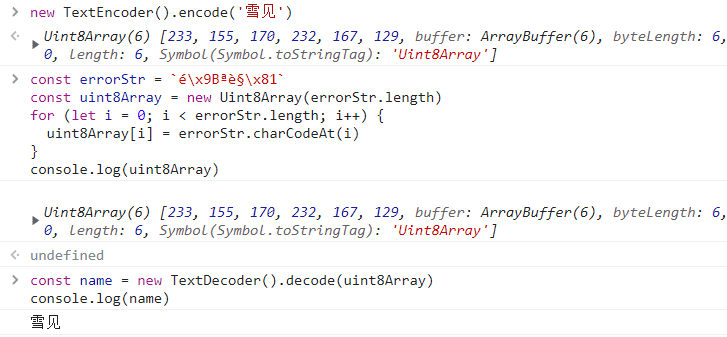
这样就还原出了原文件名。
顺便一提,TextEncoder 和 TextDecoder 都是默认把字符视为 UTF-8 编码处理。
不过 TextDecoder 可以把 雪见 的 Buffer [233, 155, 170, 232, 167, 129] 解析回 雪见,但是为什么我的后端解析库却逐个字节解析呢?我把数据发给后台的时候已经把字符编码成了 Buffer 了啊。
在编码文件的二进制数据时,我动过一个歪脑筋,因为把字符串和文件都编码成 Uint8Array 有点麻烦,所以我想如果能把文件转换成字符串,直接拼接岂不是很方便吗?
我尝试把文件通过 FileReader.readAsBinaryString() 转换成二进制字符串:
const str = await fileToBinaryString(form.file1.files[0])
console.log(str.length)
// str.length 等于文件体积,看起来很美好
const str2 = new TextEncoder().encode(str)
console.log(str2.byteLength)
// 但是实际编码成 Uint8Array 会发现它的字节数比实际文件体积大这个方法不可取,转换成二进制字符串之后,文件占据的体积大于原本的体积。
为什么会这样呢?readAsBinaryString 把源文件的每个字节转换成一个 UTF-8 编码的字符。在 UTF-8 编码里,值为 0 - 127 的字符占据 1 字节,值为 128 - 2047 的字符占据 2 字节,还有 3 字节的(如汉字),4 字节的(如很多 emoji 😍)。
所以通过 readAsBinaryString 得到的字符串变量所占用的内存大于源文件,并且一些单字节的数值变成了占据多个字节的不同数值。如果后端把转换后的字符串直接保存成文件,那么这个文件就是损坏的。
ps:还有个气人的事,有个阶段我上传文件一直失败(后台解析不到文件数据),浪费了快俩小时,各种研究,甚至找到了一个编码库去研究源码(然并卵),最后对比浏览器编码的数据,发现原因是我的字符串模板里少了个双引号,我的心情真是日了狗……
