


php中最常用的截取文字的函数是substr(),但是在该函数中,中文占用2个或3个长度,所以可能把汉字截断,产生乱码。
有一个办法是使用mb_substr()来截取文字。这样确实可以,因为mb_substr()把所有文字都当做一个长度,所以截取中文时是整个字截取的,不会乱码。但mb_substr()的长度计算方法和substr()不同,有时候反而不能用它。经过一番苦搜,我找到了用php的ord()函数来截取文字的办法。
这种方法的字数计算方法和substr()一致,但不会导致汉字被截断.如果指定的长度会截断汉字,它会把因截断而产生的残缺汉字扔掉(以最后截取出来的长度有可能会比指定的长度少一两位。)。
另外它的参数也只有两个,一个是字符串,一个是截取长度。没错,它不能指定起始位置。
GBK版本:
function gb2312_substr($str, $limit) {
$restr ='';
for($i=0;$i< $limit-3;$i++) {
$restr .= ord($str[$i])>127 ? $str[$i].$str[++$i] : $str[$i];
}
return $restr;
}
UTF-8版本:
function utf8_substr($str, $limit) {
$restr = '';
for($i=0;$i< $limit-3;$i++) {
$restr .= ord($str[$i])>127 ? $str[$i].$str[++$i].$str[++$i] : $str[$i];
}
return $restr;
}
function http_status($url) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_NOBODY, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_TIMEOUT, 5);
curl_exec($ch);
$status = (int)curl_getinfo($ch, CURLINFO_HTTP_CODE);
curl_close($ch);
return $status;
}
可以用这个函数来获取url请求的状态码,判断404很方便→_→
不过如果测试p站图片url的话,还得加上refer信息来绕过防盗链。
一个下载器搞得我找了好多php的东西,心好累。
先吃我大鼻孔
今天我在改进pixiv下载器,想把tag信息保存到文件名里。前两天我研究了“windows中文件名最大长度的问题”,也是为这个做准备。我很快把获取tag的代码写好了,也在php里限制了文件名最大长度。但是做完之后感觉有点不对劲。怎么不对劲呢?下载图片的失败几率比以前大大提高了。错误都是:
Warning:fopen() Invalid argument
那么到底文件名哪里不对呢?这问题折腾了我五六个小时,我下班都没回去,坐在办公室里还在研究这个问题。天见可怜,我终于还是找到了问题的真相。
问题还是出在长度上。
windows计算文件名(包括路径)都是按【字数】算的,也就是说,不管你是中英混合还是怎么的,都能写满256个字。
我以为用php去创建文件也可以这样,于是我在php里用mb_strlen()函数去计算字数,这个函数也是把一个文字当做一个长度算。结果我这样做是错的,php虽然也会限制文件名和路径长度之和不能超过256个字符,但它真的只是字符长度,不是字数。所以php里操作文件时,涉及到文件名长度,要使用strlen()函数。
strlen()的计算方法是,英文占一个字符,而中文字符在gbk编码中算两个字符,在utf8编码中算三个字符。还好我使用的gbk编码,否则能用的字数要更少了。
下面这个路径在php的gbk编码中算做256长度(字节?):
F:\wamp\www\t/pixivimg/专辑1422_ 【一无所有的“死亡回归”!】Re 从零开始的异世界生活特辑 /56938050_p0_tag-ナツキスバル,Re ゼロから始める異世界生活,スバル,菜月昴,ゼロから始める異世界生活,リゼロ,リゼロ500users入り,Re ゼロから始める異世界00usersxxxxxxx入り.jpg
当然,用windows的计算方式,刚到170个长度。
好吧……为了在有限的长度里多给tag腾腾地方,我把文件名里很多东西都去掉了。标题啊,日期啊什么的都扔了,只留下图片id和tag。现在的文件名是这样的:
19566474_p0-よんでますよ、アザゼルさん。,十点じゃ足りません!,ふつくしい,なにこれ綺麗,サラマンダーwwwwww,一体だけ浮いてるw,まんまですよ、マンダはん,アザゼルさん1000users入り,キャプショ.jpg
这个长度已经接近极限了。心好累,感觉不会再爱了。
最近有个功能需要判断字数。PHP 中有很多函数可以计算字符串的长度,如strlen,mb_strlen,mb_strwidth。测试如下:
echo strlen("你好ABC") . "";
# 输出 9
echo mb_strlen("你好ABC", 'UTF-8') . "";
# 输出 5
echo mb_strwidth("你好ABC") . "";
#输出 7
可以看出,strlen 把中文字符算成3个字节;mb_strlen 不管中文还是英文,都算1个字节;而 mb_strwidth 则把中文算成2个字节。
我需要的是字数而不是字节数,所以mb_strlen是我想要的。但是要注意,“把汉字算做1个长度”必须指定为utf-8编码,否则它也会把汉字算做3个字节。
另外,截取字符串时,也可以用mb_substr指定utf-8编码,将汉字算做一个长度。如:
echo mb_substr('这样一来我的字符串就不会有乱码^_^', 0, 7, 'utf-8');
这个输出需要页面环境有编码才不会乱码。例如将此结果输出到html中,输出的字符会使用html页面的编码。如果单独写这一行php输出,还会是乱码。
此脚本已停止维护,请使用新版本。
以下内容作废。
2016.12.6
最近ikanman的图片格式有很多变成了.jpg.webp格式的,windows原生不支持此格式。有两个解决办法:
1.安装“WebP Codec for Windows”这个程序,安装之后可以使用windows图片查看器查看webp格式的图片。
2.安装支持webp格式的图片查看器,比如honeyview。
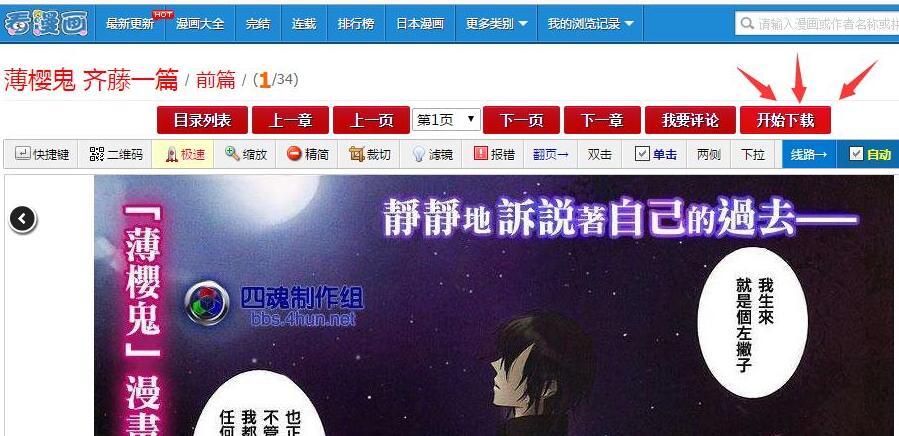
首先下载上面的文件,解压后把php文件丢到127.0.0.1里(如果放在其他网络位置,需要修改js中phpPatch的值为对应值)。
配置完成后,打开漫画阅读页面。
如果已经安装了UserScript,则可以看到页面顶部的页码区域会出现一个“开始下载”按钮(见上图)。
如果没有使用UserScript,则可以复制js文件的全部代码,在漫画阅读页面的浏览器控制台里执行js代码。正确结果也是出现“开始下载”按钮。
点击“开始下载”按钮即可开始下载。下载器会这个页面一直下载到漫画最后一页,保存到硬盘上(就是说可以从漫画的任何页面开始往后下载)。
下载时页面顶部会出现进度提示区域,点击可以设置是否停止下载。
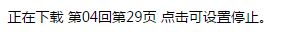
下载器默认会在ikanman_down.php所在的文件夹里创建一个ikanman文件夹,之后会把下载到的漫画存放在里面,如图:
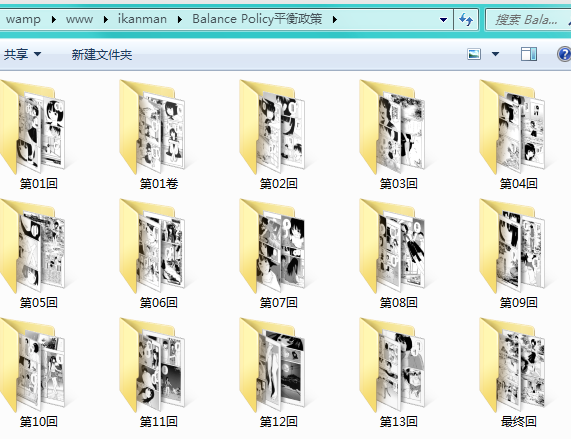
如果想修改存放位置,可修改php中$rootdir变量的值。
本文中说的比较简略,详见说明文档。如果遇到问题可以再问我。QQ交流群:499873152
ps:如果提示缺少msvcr110.dll,请安装VC++2012运行库的32位版本,之后重新启动wampserver。
ps2:如果下载中出了问题导致没下载完(如页面崩溃什么的),可以看一下下载到哪一页了,然后打开下载到的那一页,继续下载。
Read More →
我在做pixiv图片下载器的时候,需要用php在硬盘上建立文件夹。有些文件夹的名字含有中文,那就需要转换为gbk编码,不然出来是乱码。
之前我是这样转换的:
iconv('utf-8', 'gbk', "【20周年♡】魔卡少女樱特辑");
但有时候会遇到问题,例如上面“周年”后面的心,在gbk里面没有,转换的时候会出错。一旦出错,这条语句就停止执行了,我们只能得到前半截“【20周年”,后面什么都没了。
今天这个现象又发生了,上网查了查,原来加上ignore参数就可以忽略出错的字符,继续转换。
iconv('utf-8', 'gbk//ignore', "【20周年♡】魔卡少女樱特辑");
现在,这个心会被忽略掉,我们能得到较为满意的结果“【20周年】魔卡少女樱特辑”。
另外还有个参数//TRANSLIT是遇到错误时替换为相近的字符,但是这个效果很难说啊,我是没有用。
<?php
header("Access-Control-Allow-Origin:http://spotlight.pics";);
$url=$_GET['url'];
$refer = "http://www.pixiv.net/";;
$cookie = "key1=value1;key2=value2;key3=value3";//设置cookie信息
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_BINARYTRANSFER, true);
curl_setopt($ch, CURLOPT_REFERER, $refer);
curl_setopt($ch, CURLOPT_COOKIE, $cookie);//携带cookie信息
$cexecute = curl_exec($ch);
if ($cexecute) {
echo $cexecute;
}else{
echo "false";
}
curl_close($ch);
?>
主要就是带注释的那两句。$cookie里的值只是个示范,我当然不会把自己的cookie暴露出来滴~设置好一些必须的cookie就能以登录状态抓取网页了。
今天有人想让我给pixiv图片下载器增加下载pixiv Spotlight的功能。这里面涉及到两个问题,一个是跨域,一个是登陆状态。
首先看看跨域问题。pixiv Spotlight的主域名不是pixiv.net,而是spotlight.pics。以前我抓取网页没有遇到跨域问题,因为那时全都是在pixiv.net域中操作的,用ajax就可以获取到其他网页的内容。现在不行了,只能在自己服务器上做了个如上的php文件,在header中设置Access-Control-Allow-Origin来接收来自pixiv Spotlight的请求。接收到请求后,就去抓取网页。
这时就遇到第二个问题了。因为抓取是从我服务器发出的,不是从浏览器发出的,所以没有cookie,抓取到的网页是未登录时会出现的注册页面。后来搜到了CURLOPT_COOKIE这个参数,可以在curl中携带cookie信息,这样就像正常登陆一样,能获取到登陆后的页面了。这样才解决了问题。
现在我php里设置的cookie信息是我自己的,一直使用现在的cookie值不知道以后会不会失效。只能用着看了。
跨域问题是web开发中一个常见的问题。例如说从网站a.com上用ajax把一些信息发送到b.com上,就会产生跨域问题。浏览器为了安全会阻止这个跨域请求,并产生一个跨域错误。
如果接收方b.com对应的文件是php文件,则可以在header函数中指定Access-Control-Allow-Origin的值,来设置哪些域名可以向这里发送跨域请求。
示例:
ajax请求如下(本彩笔使用了jq的ajax):
$.ajax({
url:"http://127.0.0.1/t/t.php",
type:"get",
async:true,
cache:false,
dataType:"text",
success:function (data) {
alert(data);
}
});
php文件添加Access-Control-Allow-Origin头:
header("Access-Control-Allow-Origin:*"); // 允许指定域名发起的跨域请求
//header("Access-Control-Allow-Origin:http://tieba.baidu.com"); // 允许指定域名发起的跨域请求
echo "saber";
这就ok了。
Read More →
dedecms后台有自定义表单功能,将前台表单数据保存到后台里。但是要查看只能去后台看,时间长了感觉非常的麻烦。于是我找到了将表单信息自动发送到邮箱的办法。
1.确保你有个开启了IMAP/SMTP功能的邮箱。
2.在 dedecms后台→系统→系统基本参数→核心设置中,设置你邮箱的smtp信息。
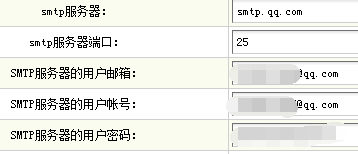
这里填好就行了,设置里有个“网站发信EMAIL”不用管。
3.在 dedecms的plus文件夹下找到diy.php,在85行的位置有如下语句:
$query = "INSERT INTO `{$diy->table}` (`id`, `ifcheck` $addvar) VALUES (NULL, 0 $addvalue); ";
在其下方添加发送邮件的代码即可(前两行要自己设置一下):
$mailtitle = "信息表单";//邮件标题
$mailbody = "姓名:{$name}\r\n联系方式:{$lianxi}";//花括号里是该元素的name属性
$headers = $cfg_adminemail;//用我们刚才设置的管理员邮箱发送
$mailtype = 'TXT';//邮件类型为文本类型
require_once(DEDEINC.'/mail.class.php');//加载 dedecms的邮件库
$smtp = new smtp($cfg_smtp_server,$cfg_smtp_port,true,$cfg_smtp_usermail,$cfg_smtp_password);//创建smtp服务
$smtp->debug = false;//不启用调试
$smtp->sendmail($cfg_smtp_usermail,$cfg_webname ,$cfg_smtp_usermail, $mailtitle, $mailbody, $mailtype);//发送邮件(收件人,网站名,发件人,邮件标题,邮件内容,邮件类型)
注意,第二行里按需填写表单控件的name值。如果你有很多表单项,可以一个个都写出来。

至此,当有表单提交时, dedecms就会自动往邮箱里发一封邮件了(自己往自己邮箱里发一封邮件)。
Read More →
