


最近我让 AI 帮写了一些脚本,都是和文件操作有关的。前段时间写了个 ps 脚本,刚才又写了个 bat 脚本,都因为编码问题踩了坑。
bat 脚本需要用记事本保存为 ANSI 编码,不能使用 UTF-8,否则会导致脚本内容解析错误而无法运行。
而且还有个坑:我的系统是 Windows 11 简体中文版,AI 说 ANSI 编码在简体中文系统中对应 GBK/GB18030,但我在 VSCode 里保存成这两种编码依然报错,最后只能用记事本保存为 ANSI 编码的才能正常运行。
PowerShell 5.1 脚本需要保存为 UTF-8 with BOM 编码,不带 BOM 不行。
更新:PowerShell 有个开源版本(PowerShell 7),它是需要独立安装的,也是独立运行的(与 Windows 自带的 PowerShell 5.1 并存)。它的脚本后缀名也是 .ps1,但是不需要带 BOM,不会因为编码问题踩坑了。而且 PS 7 对路径、文件名里的中文支持更好,我现在已经用它替代了 PS 5.1。
ConvertZ(最新版本8.02)是一款适用于中文文本的Big5/GBK/Unicode/UTF8内码转换器,十分好用。
我有时需要对整个网站内容进行批量替换,但如果网页编码是gbk(或gb2312)的,我就会感到有点头疼。我使用的编辑器sublime text3虽然有插件使它可以支持gbk编码,但这个插件并不可靠,偶尔会导致文件保存时变成乱码,十分坑爹。而ConvertZ则可以方便的将html文件批量转码,这使我十分感动。
使用步骤如下:
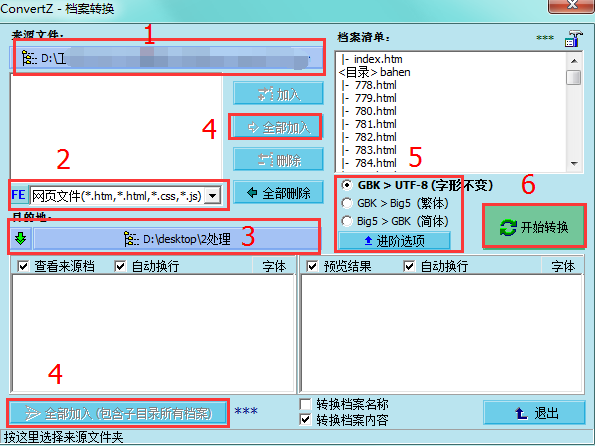
首先点击1,选择要转换的文件所在的文件夹。
之后点击2,选择需要转换的文件类型。
之后点击3,选择输出文件夹。
之后点击4(加入按钮)上面的加入按钮不会添加子文件夹里的文件,下面的则会添加子文件夹里的文件,按需使用。
之后到区域5选择转码转换方向(gb2312选择gbk就行),如果需要的话可以点击“进阶选项”选择更多编码类型。
最后点击6,即可开始转换。
转换速度很快,而且如果使用了“包含子目录”的加入按钮,那么转换后的文件还会按原文件夹结构存放,实在是方便。确认转换无误后覆盖掉原文件夹就行了。
对于html文件来说,用ConvertZ2转换成utf-8编码的话,除了内码变化之外(utf-8的文件体积比gbk的文件体积要大),charset也会自动更改为“utf-8”,很省心。
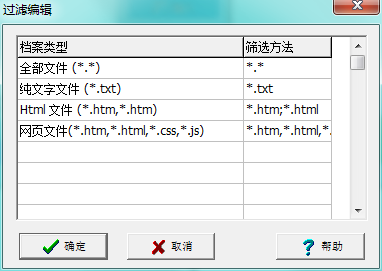
ps:第2步那里可以点击左侧的蓝色按钮添加自己需要的文件类型:
我在做pixiv图片下载器的时候,需要用php在硬盘上建立文件夹。有些文件夹的名字含有中文,那就需要转换为gbk编码,不然出来是乱码。
之前我是这样转换的:
iconv('utf-8', 'gbk', "【20周年♡】魔卡少女樱特辑");
但有时候会遇到问题,例如上面“周年”后面的心,在gbk里面没有,转换的时候会出错。一旦出错,这条语句就停止执行了,我们只能得到前半截“【20周年”,后面什么都没了。
今天这个现象又发生了,上网查了查,原来加上ignore参数就可以忽略出错的字符,继续转换。
iconv('utf-8', 'gbk//ignore', "【20周年♡】魔卡少女樱特辑");
现在,这个心会被忽略掉,我们能得到较为满意的结果“【20周年】魔卡少女樱特辑”。
另外还有个参数//TRANSLIT是遇到错误时替换为相近的字符,但是这个效果很难说啊,我是没有用。
