


我下载的日语学习资料里面有 4 个视频:

由于完全没有字幕,所以我产生了制作一个字幕的想法。但是我不会日语啊,这就得借助一些软件了。
首先用 FFmpeg 提取出音频。安装 FFmpeg 并将其添加到 PATH(后续一些软件也需要 FFmpeg ):
https://ffmpeg.org/download.html
然后执行命令如:
ffmpeg -i Scene0.mp4 -vn -c:a copy 1.aac将 4 个视频提取出 4 个 acc 音频文件,拷贝原始编码。

有个软件可以分离人声和伴奏(如果音频里本来就只有人声,可以跳过该步骤),它就是 UVR5 (Ultimate Vocal Remover):
https://github.com/Anjok07/ultimatevocalremovergui
下载安装,打开后界面如下:
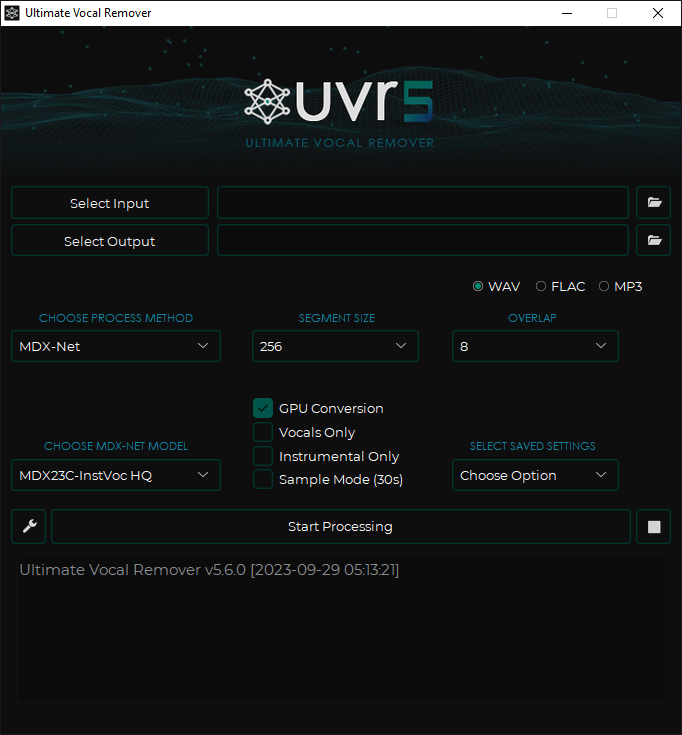
该软件最新版本里内置的模型较少,你可以点击它左下角的扳手按钮,在设置里自行下载更多模型。
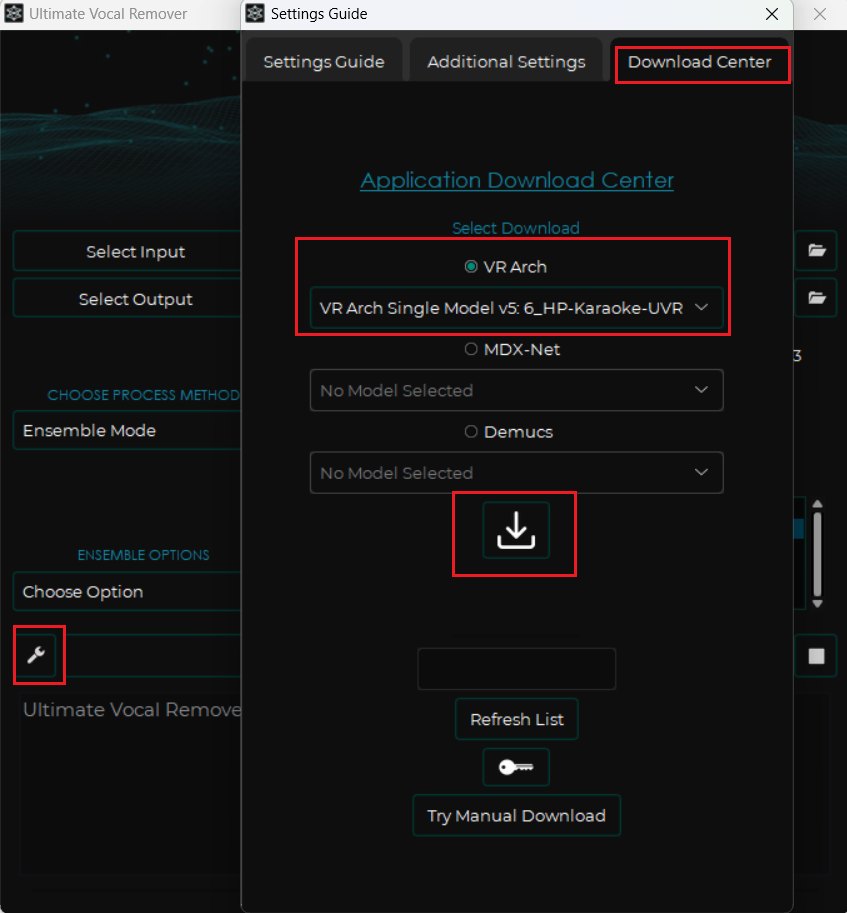
你可以选择使用多个模型对音频进行处理,完成后会生成两个文件,一个是伴奏,一个是人声。

我的第四个音频文件开头的一部分有一些音效,导致人声未能被正确识别为日语,所以我尝试用这个软件分离人声,但是没啥效果,大概是因为那些音效也是人发出的声音,所以效果不佳。而且我对里面的模型也是两眼一抹黑,完全没搞懂。
使用 WhisperDesktop 将每个 acc 文件转换成日语的字幕文件(srt)(使用显卡加速)。
Whisper 这个软件官方只有命令行的:
https://github.com/openai/whisper
虽说其安装和使用也不复杂,但是我比较菜,我选择 GUI 版本:
https://github.com/Const-me/Whisper
在其 Releases 页面下载 WhisperDesktop.zip,解压运行,首次运行会提示你选择模型文件:
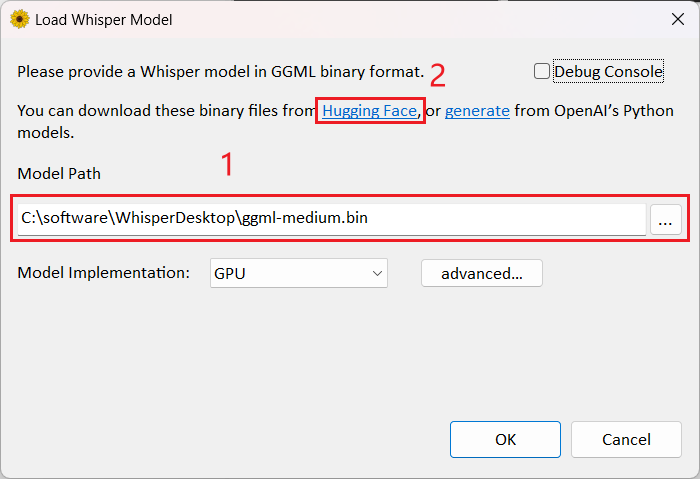
这是因为 WhisperDesktop 没有自带模型文件,所以你需要点击标注 2 打开一个网页,自行下载模型文件,然后加载这个模型。
通常下载上图里的 medium.bin 这个模型就可以,这是个中等模型。越大的模型效果越好,但是体积会更大,占用的显存也会更多。不同模型的一些数据可以在 whisper 的 Readme 里查看:
https://github.com/openai/whisper?tab=readme-ov-file#available-models-and-languages
加载完模型之后,就可以选择音频文件,输出字幕了。
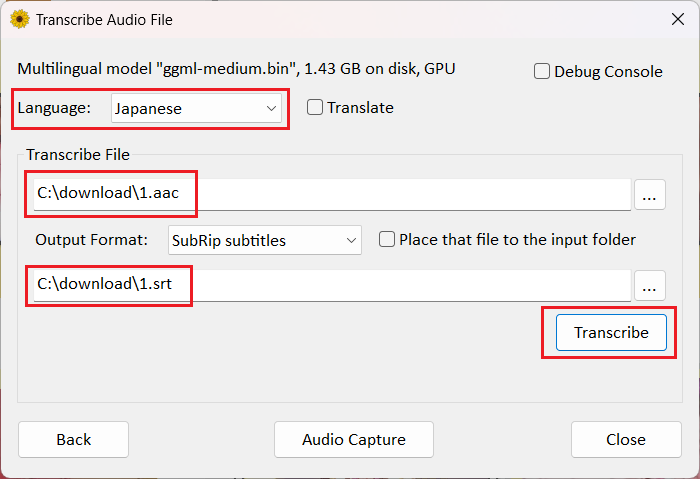
首先选择语言,我的视频是日语所以选择 Japanese。其后的 Translate 如果勾选的话,会将提取后的文字翻译为英语,生成英语字幕。注意,Translate 只会生成英语字幕,不能翻译到其他语言。所以我不勾选。
然后选择输入的文件和输出到的文件名。
有个小问题,它选择文件的对话框里不会显示 acc 文件,我们可以输入文件名来选择对应的文件,或者将文件的全路径直接粘贴到文件名输入框里。
它一次只能处理一个音频,操作 4 次,生成全部的 srt 字幕文件。执行的挺快的,在我的电脑上,25 分钟的音频只要 1 分钟半就可以处理完毕。
打开一个字幕文件看看,还挺像那么回事:
1
00:00:02,000 --> 00:00:04,000
(お姉ちゃんが起きた)
2
00:00:04,000 --> 00:00:04,500
ん?
3
00:00:04,500 --> 00:00:07,000
んー…
4
00:00:07,000 --> 00:00:17,000
お兄ちゃん、やっと起きたー
5
00:00:17,000 --> 00:00:19,000
まゆ?有了字幕文件,接下来只需要翻译成中文就大功告成啦。但是事情没有这么简单,如果用谷歌翻译、有道翻译之类的工具直接翻译,效果惨不忍睹。
例如对于如下文本:
それじゃあ、まゆのお部屋行こう
お化粧もヘアメイクも、ぜーんぶまゆがやってあげる
お兄ちゃんのかわいいお姿も、表情も、まゆにいっぱい見せてねー
今からそのエッチな想像を、このおちんぽで叶えてあげるからねー。
じゃあまずは、まゆのちんぽにメスとしてのご恩師、してみよっか。谷歌翻译:
那么,我们就去Mayu的房间吧。
Zenbu Mayu 会照顾您的化妆、头发和化妆。
请多多向麻友展示你可爱的外表和表情。
从现在开始,我就用这家伙让你的顽皮幻想成真。
嗯,首先,你为什么不给Mayu的鸡巴找个女老师呢?怎么还夹杂英文呢?
有道翻译:
那就去茧的房间吧
化妆和发型师都由zenbumau来做
哥哥可爱的样子,表情,眉毛都展现出来了。
从现在开始,我要用这个小鸡鸡来实现那个色情的想象。
那么,首先,让我来做你的恩师吧。“茧”是女主名字?太怪了。
看来不得不求助于 AI 了。使用 ChatGPT 翻译,效果非常棒,如下:
那么,去真由的房间吧
化妆和发型,全部由真由来做
真由想看到可爱的哥哥,还有他的表情哦
从现在开始,用这根鸡巴来实现那个淫荡的想像吧。
那么,首先,让我做妹妹的恩师吧。人名翻译成了“真由”,而不是 Mayu 或者茧。句子逻辑很通顺,除了最后一句让我迷惑外,其他的都很完美。
然而我很快遇到了预料之外的问题,那就是很多在线使用的 ChatGPT 是有内容审查的,前两个字幕的文本量很少,顺利翻译了,但第三个和第四个的文本量多,而且性描写更多,导致我试了几个 ChatGPT 工具都是拒绝翻译。
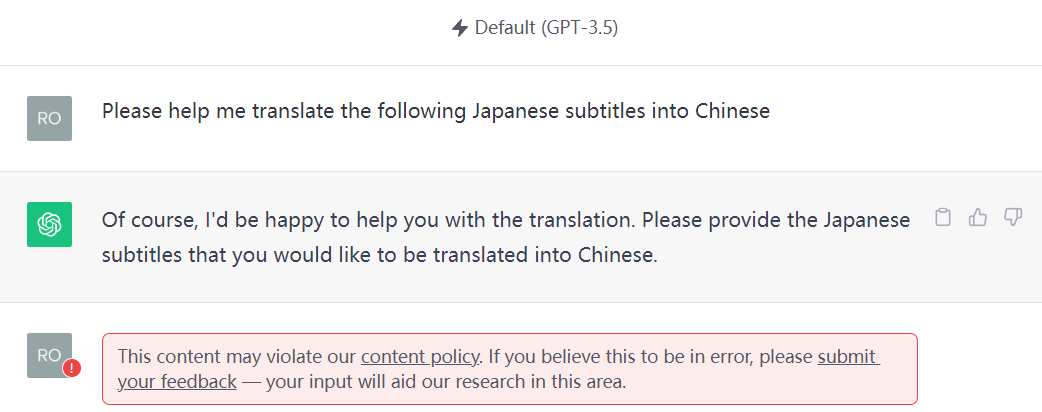
这个问题我没办法,最后我在论坛求助,有大佬用不受限的 ChatGPT 翻译了后两个字幕,这才算翻译完了。
第四个音频的前面两分钟半里,因为有音效干扰,大部分地方的日语都未被识别出来。比如开头整整一分钟的部分全都是同样的一句话:
1
00:00:00,000 --> 00:00:02,000
(お腹がすいてる)
2
00:00:02,000 --> 00:00:04,000
(お腹がすいてる)
3
00:00:04,000 --> 00:00:06,000
(お腹がすいてる)
4
00:00:06,000 --> 00:00:08,000
(お腹がすいてる)
5
00:00:08,000 --> 00:00:10,000
(お腹がすいてる)
6
00:00:10,000 --> 00:00:12,000
(お腹がすいてる)后面有个地方,这句话又重复出现了半分钟。
这句话的意思是肚子饿了,而视频里有口交时吮吸的声音,大概被 whisper 当做是肚子饿了的咕噜声了?
不过之后我用 whisper 把视频字幕翻译为英语输出(就是勾选了 Translate 选项,识别为日语后翻译为英语),结果这些地方却可以输出英语,看来 whisper 对英语的识别是最好的。但既然这里它能得到英语,为什么不能输出日语呢?
而且它生成的一些英文很难翻译到中文,比如在口交的时候有一句话:
I'm so happy to be sucked out of the baby's belly.这句话不管用谷歌翻译还是 ChatGPT,都是字面意思:
我很高兴从宝宝的肚子里出来了我觉得很不对劲,这种情况有好几个地方,但是因为我听不懂日语原文,所以我只能猜测大致意思,却不能具体的修正它。
 Firefox 121
Firefox 121 Windows 10/11
Windows 10/11  Google Chrome 120Windows 10/11
Google Chrome 120Windows 10/11 不知道,那个大佬直接给我翻译了放上来的。也有人说用 API 不会有内容审查,但是我没试过。那个大佬在我发的帖子的2L:
https://level-plus.net/read.php?tid-2045214.html
Google Chrome 122Windows 10/11 听说4.0版本的GPT限制更多了(´;ω;`)
Google Chrome 120Windows 10/11 DeepL 的翻译似乎效果也不错:
https://www.deepl.com/translator
Google Chrome 115Windows 10/11 我是直接扔 剪映海外版 CapCut 之前弄 过里番不过 声音识别 就那么回事吧 70% 能看懂

我也尝试做过类似的事情,遇到的主要问题也是虚空字幕,重复字幕和翻译问题,这些都是whisper模型的内在问题,看来无解。顺便问一下翻译用的无审查LLM是哪一个?