


Chrome 浏览器的优点,不仅在于它运行快、对新技术的支持快,其实它也有强大的纠错能力。这里主要讲讲编码错乱的方面。(主要和Firefox 对比)
测试环境:
Windows 7 SP1 x64
Chrome 65.0.3325.181
Firefox 59.0.2
情景1:网页编码错乱
如果网页的编码设置错乱,或者压根没设置编码,Chrome 也可以尝试正确显示。Firefox 就歇菜了。
如下网页代码:
<!DOCTYPE html> <html> <head> <meta charset=gb2312"utf-8"> </head> <body> 你是我的骂死他吗 </body> </html>
charset 设置的不对,这个情况我遇到过。以前用转码工具把一个gb2312 编码的网站转换为 utf-8 编码,那个软件会自动把 charset 的“gb2312”替换成“utf-8”。可能原网页不太规范,有少数页面在处理后变成了这种奇葩的情况。
Chrome 对此仍然可以正常显示,Firefox 就乱码了。


Chrome 没有任何报错信息,估计是默认按 utf-8 处理了。
Firefox 报了个错误:
HTML 文档使用 meta 标签声明了一个不支持的字符编码。该声明被忽略。
把设置 charset 的那一句完全删掉也是一样的情况。
情景2:图片的 Content-Type 设置不对
今天发现的,bilibili 的视频封面图,我们看到的都是小图,小图的 Content-Type 设置的是图片。但是大图的 Content-Type 竟然是text/plain。
如下图片网址:
https://i2.hdslb.com/bfs/archive/d1054641536e8af64175e4a33bd763169f834650.jpg
Chrome 仍然可以将它解析为图片,但是 Firefox 就真的当成纯文本来显示了。
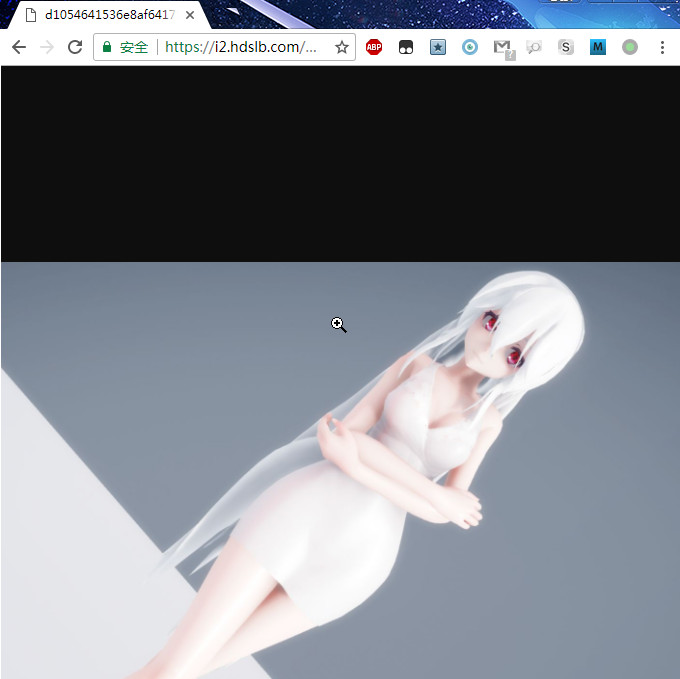
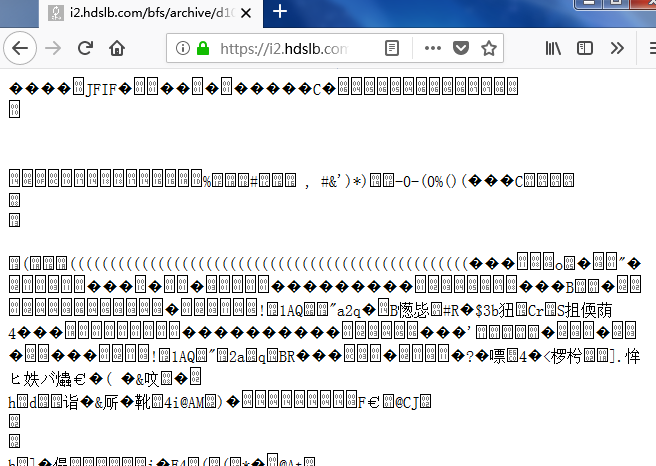
Firefox 报错:
纯文本文件的字符编码未声明。如果该文件包含 US-ASCII 范围之外的字符,该文件将在某些浏览器配置中呈现为乱码。该文件的字符编码需要在传输协议层声明,或者在文件中加入一个 BOM(字节顺序标记)。
情景3:打开未设置编码的txt
前两天我发了一本小黄书:希灵淫国.txt
点击链接默认是在浏览器里打开这个txt文档的。(服务器的返回头里没有 Content-Type 信息)
Chrome 依然可以正常显示,Firefox 不出意外的乱码了。Firefox 的报错信息同上。
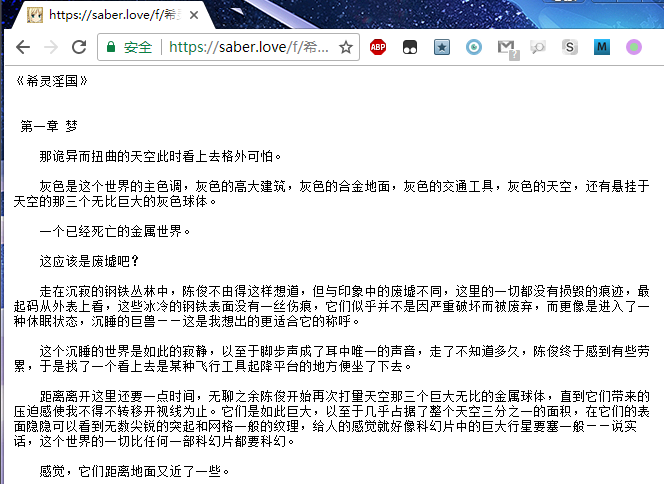
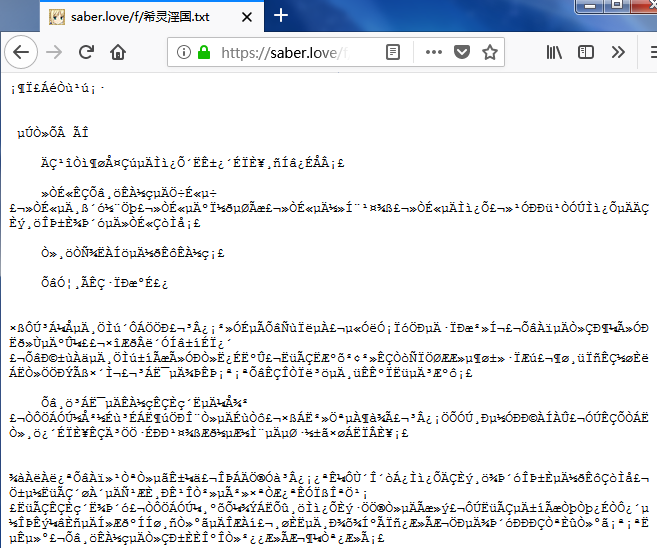
其他问题:
Firefox 不完全支持 CSS 的 ::selection 规则,还是需要用 -moz- 前缀。Chrome 很久以前就不需要了。(这个规则可以修改选择网页元素时默认的蓝底白字效果)。
我写的 pixiv 下载器,在 Firefox 上下载文件时,会发生内存泄漏。在 Chrome 上面就不会。
用惯了Chrome 的梯形标签页,再看看现在 Firefox 的长方形标签页,很不适应。太过呆板了,而且互相之间紧挨在一起,没有空隙。感觉很有压迫感。
不过 Firefox 看 pdf 文档的时候比 Chrome 好很多,能提取目录,字体也是宋体。(Chrome 里看 pdf 默认是黑体)
附1:(黑 Firefox 专用)
1.event 的兼容问题,特立独行,必须为 Firefox 特殊处理
2.不支持 html5 的 datetime-local 类型的输入框。这是一个日期时间输入控件。下面的输入框在 chrome 上正常,在 Firefox 上就是一个普通的输入框:
3.一些奇奇怪怪的问题,比如:
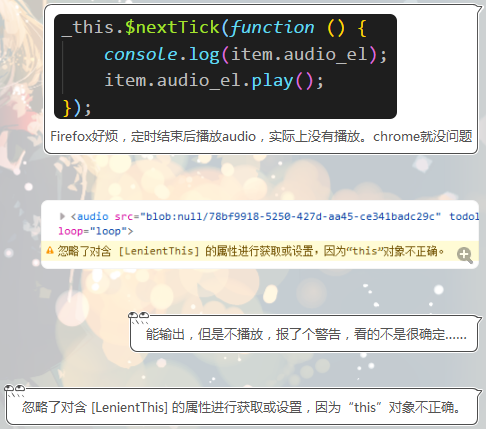
对着这个提示没搜到什么有价值的东西。打印了下 this,没感觉有问题。而且这只是个警告,就不能放行一下吗。Chrome 上一切正常。
