

12/12
2020
明明是一个很浅显的概念,却纠结了很久……大概是因为太浅了所以没什么人说吧……
DMA(Direct Memory Access,直接存储器访问)是什么不提了
DMA Latency,这边定义为DMA发出的req的上升沿到收到的rlast/wlast的上升沿经过的时间
Latency Tolerance,指DMA能容忍多长的Latency而不出错(指fifo写满或读空)
Brust Length和Waterlevel过于基础,也到处有人教,不提。
讨论都是基于以下模式:以rdma为例,IP需要持续读取数据流,中断了就会出问题。数据是经过DMA从内存拿过来的,内存是以BL模式运行(不考虑DDR的问题……)。DMA本身有异步fifo,能在sram暂存数据。当然也是遵循的waterlevel模式……
fifo每能存下一次BL就发一个req,因此可能有多个req等待内存响应
忽略fifo和位宽转换等因素造成的latency,集中于“理想”DMA情况
定义参数:
IP侧:
频率fip(GHz)
数据位宽Wip(bit)
SRAM大小D(bit)
BUS侧(含内存)
频率fbus(GHz)
数据位宽Wbus(bit)
BL长度BL(bit)
当ip发出第一个req,此时dma sram剩余数据量应为waterlevel=D-BL(设位宽以及BL互相匹配,可不用考虑余数)
这些数据能坚持下去而不产生fifo读空的时间t1=waterlevel/(fip*Wip) (ns)
假设读空时正好接续上BL,那么BL持续时间t2=BL/(fbus*Wbus) (ns)
那么此时的Latency就正是最大值,也即Latency Tolerance ttol=t1+t2
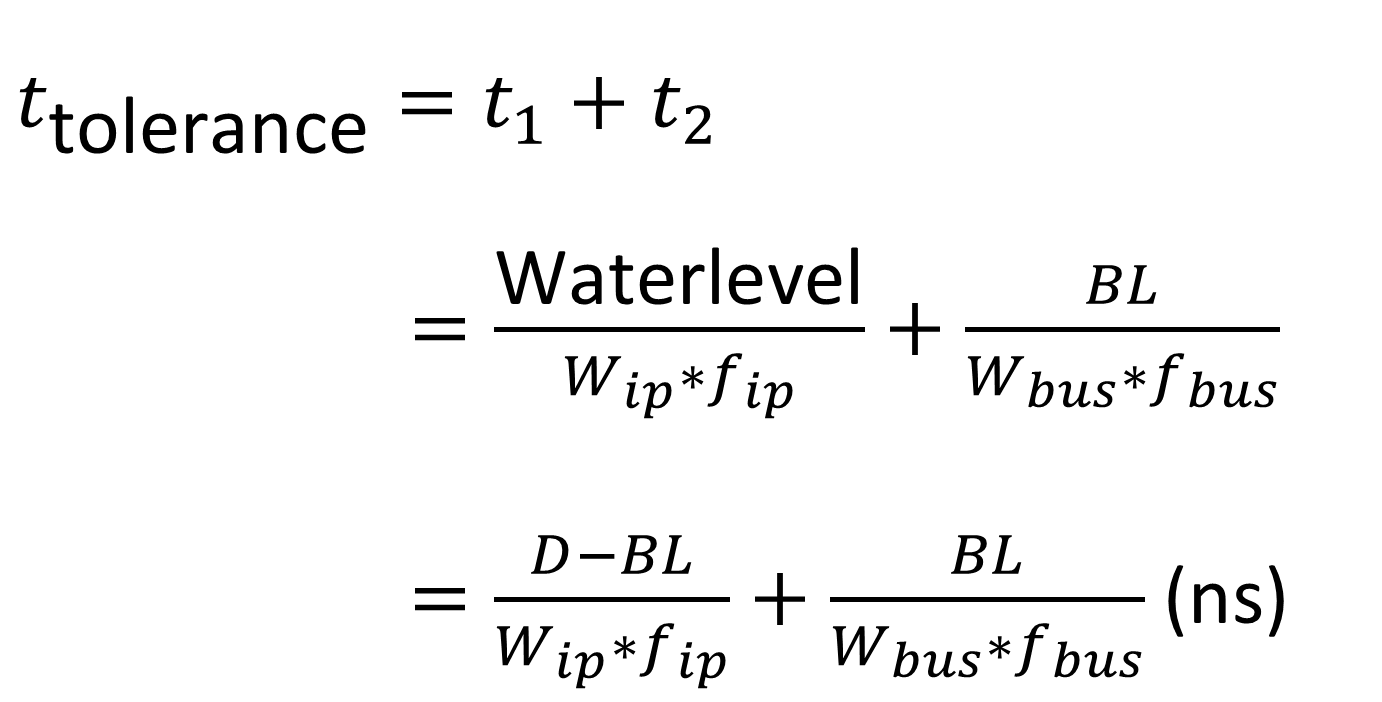
此时ttol和fip、Wip、fbus以及Wbus的关系已经清楚了,与D的关系也很明显。为了理清BL的问题,进行如下变形:
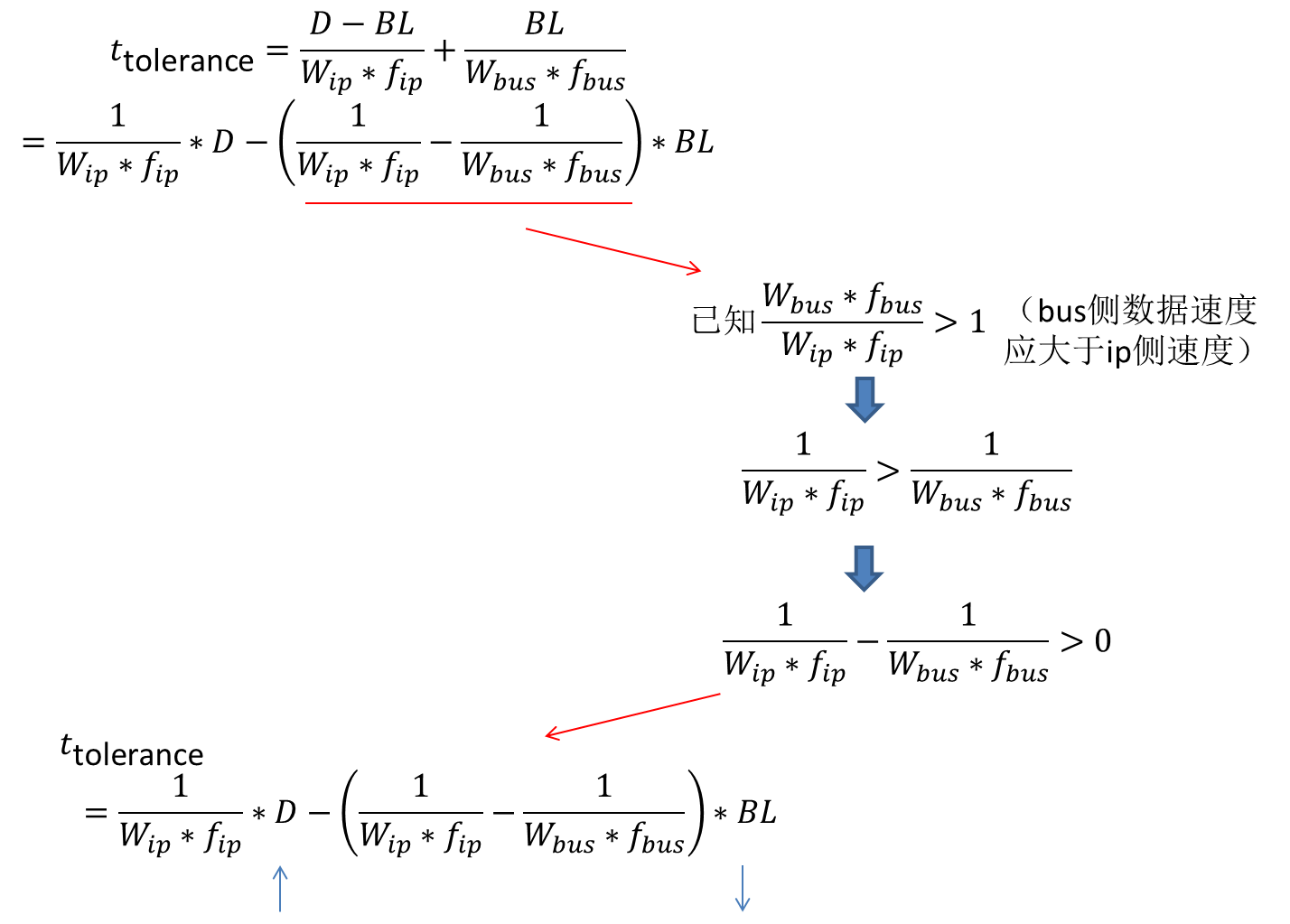
那么可以注意到BL越大ttol越小。
新的问题又来了,BL怎么处理?
BL太小显然会导致各个部分频繁处于目标切换之中,切换是需要时间的,并不是个好情况。
此处姑且再引入一个东西:队列长度n。
前面有提到dma每能接受一次BL就发一个req,那么对于一套完整的系统,假设i个rdma,j个wdma(参数与前文一致),在arbiter中队列最长能够储存n个req(再加上一个进行中的)。
极端情况下,每个dma都在发出请求,这时候大家的tlatency也就很长了。
这时候,每个dma在最极限的情况下就是都刚好从内存收/发waterlevel量的数据,刚好维持到下一次。而为了撑满工作时间,不让dma arbiter无事可做,也不能发的太多。怎么考虑?就以不发过D为限。如果接下新的BL会超过D,这一次req当然就会被扣下嘛。
那么这个情况下,平均给每个dma的BL数量为(n+1)/(i+j),那么这么多个BL就需要超过waterlevel又不能超过D。也即
(D-BL)<(n+1)*BL/(i+j)<D
解得
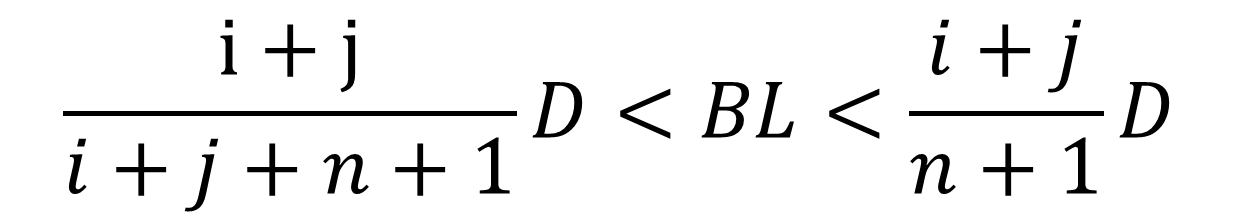
可是又有新的问题了:
i和j是ip架构决定的,但n又怎么来?
必须承认,这个问题我也无法回答。能说的就是,
你不能次次都让dma跑在latency tolerance下,这样你的sram数据是补充不及的。你可以说,平均的latency: tavg_latency满足
tavg_latency*Wip*fip <=BL
这个东西就不仅是BL的问题了,还涉及到更高层的架构,包括内存等等问题。这就不是一个我能讨论的小话题了。
总之在一般情况下,结合项目要求来考虑吧。我也只懂这么多了。



前面还行 到后面函数直接关了