




07/17
2024
在 /var/log/nginx 目录里可以查看 Ngixn 的日志文件:access.log 和 error.log,我以前没看过,今天因为我想看 PHP 的错误日志才进来看看,结果看到了好多刷屏攻击的,难绷。我的博客访客本来就少,这下看来攻击者的请求数量至少是正常用户的数十倍了。
access.log返回目录
先看访问日志 access.log,它的定义是:NGINX 在处理完请求后立即将有关客户端请求的信息写入访问日志。(查看来源)
我打开一看,通篇没别的,就几种请求在不间断的访问,每秒至少好几次请求:
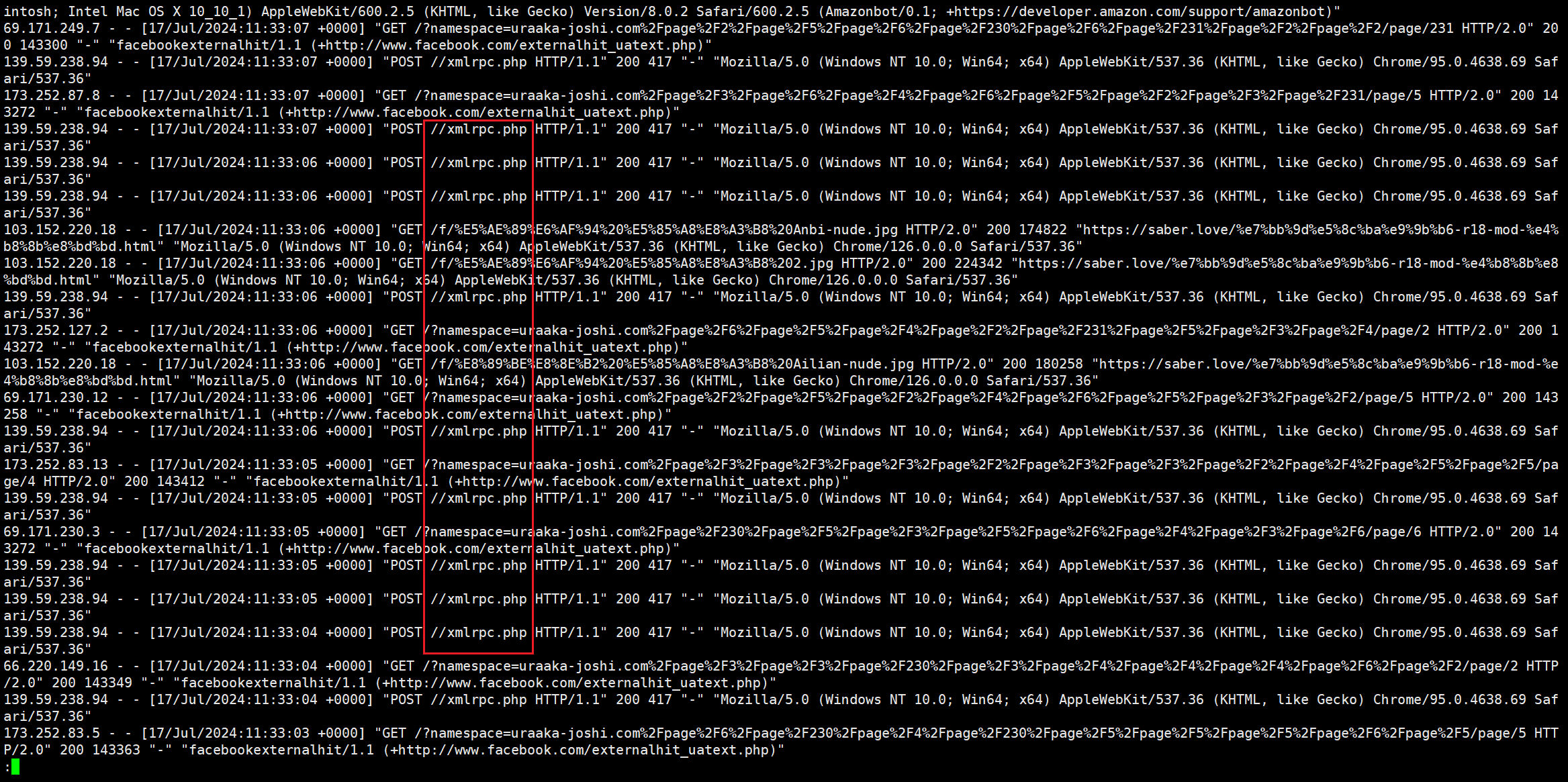
- 有个 ip 持续请求 xmlrpc.php
- 来自 Facebook 的爬虫
- 来自 Amazon 的爬虫
禁止访问 xmlrpc.php返回目录
xmlrpc.php 我平时没注意过,搜了下发现它是处理一些远程操作的,比如你可以在本地编辑器(如 VSCode 之类)里撰写文章,然后用插件将其发布到博客,这就要用到 xmlrpc.php 来处理。
通过 xmlrpc.php 提交数据时需要附带用户名和密码,这就导致有攻击者不断伪造用户名和密码进行不间断的提交,以尝试碰撞或暴力破解某些用户及其密码。
另外 WordPress 还有个叫做 pingback 的功能也用到了 xmlrpc.php,不过我也没有使用。(关于 Pingback)
我用不到 xmlrpc.php,所以直接禁用它就好。搜了下有个办法是在 functions.php 里添加一行代码来禁用:
// 禁用 xmlrpc
add_filter('xmlrpc_enabled','__return_false');我试了下不行,也许它禁用了 xmlrpc 的实际功能,但是 xmlrpc.php 这个文件还是在被不停访问。所以我用了另一个办法,在网站的 nginx 配置里直接禁止了对此文件的访问:
location ~* /xmlrpc.php {
deny all;
}之后查看日志,果然再也没有 xmlrpc.php 的身影了。攻击者访问 xmlrpc.php 时会被拒绝,并在 error.log 里生成日志。这样 access.log 里的干扰内容就少了许多。

Facebook 爬虫返回目录
现在大部分请求都是 Facebook 的爬虫了,大约每秒请求 4 次左右:
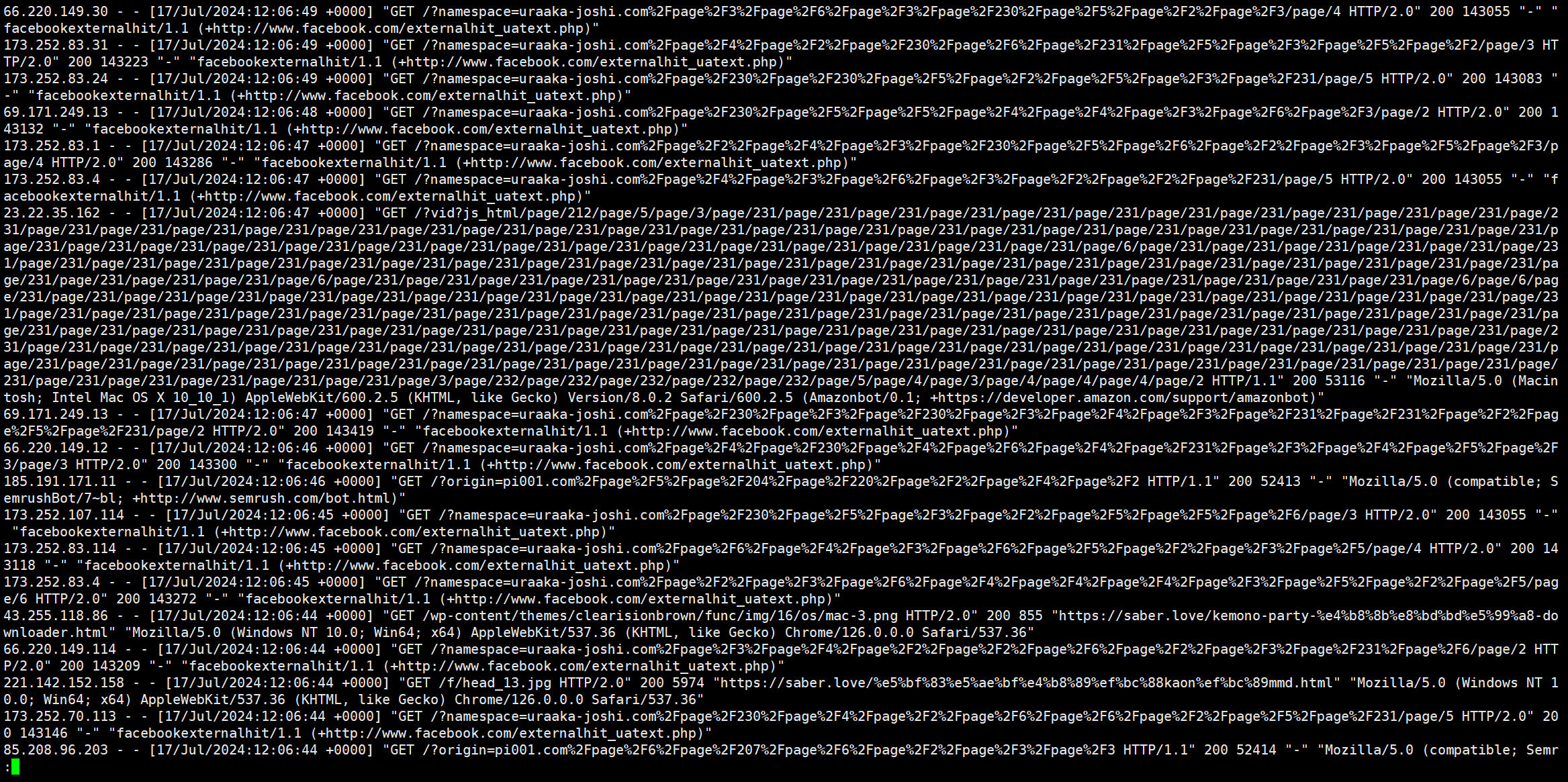
173.252.107.18 - - [17/Jul/2024:12:50:14 +0000] "GET /?namespace=uraaka-joshi.com%2Fpage%2F230%2Fpage%2F2%2Fpage%2F5%2Fpage%2F4%2Fpage%2F231%2Fpage%2F3%2Fpage%2F231%2Fpage%2F2%2Fpage%2F3/page/6 HTTP/2.0" 200 142897 "-" "facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)"
它的访问有一些特点:
- ip 不固定,但是有几个较为固定的 ip 段
- 几乎所有请求都与 uraaka-joshi 有关
奇怪,博客里仅有一篇文章与 uraaka-joshi 有关,是我几年前写了个它的下载器,发了一篇文章。网址如下:
https://saber.love/uraaka-joshi-com-downloader.html
问题在于这爬虫访问的是实际上不存在的网址:
/?namespace=uraaka-joshi.com%2Fpage%2F3%2Fpage%2F5%2Fpage%2F6%2Fpage%2F6%2Fpage%2F3%2Fpage%2F5%2Fpage%2F4%2Fpage%2F6/page/5
我的博客根本没有 /?namespace= 这种请求路径,所以它会直接跳转到首页。而且从这个网址后面看,似乎是在访问后面的分页 page/5(并且还产生了错误的循环),但这个文章以及这个 tag 都仅仅一页,不存在分页。所以我想不明白这种请求网址是怎么来的。
另外我有个疑问,Facebook 爬到的内容会在什么地方使用,在什么情况下会被展示出来?
Amazon 爬虫返回目录
它的请求频率比较低,大约每个七八个 Facebook 的爬虫,就会出现一次 Amazon 的爬虫。
它抓取的也是个不存在的网址,并且分页格式产生了错误的循环。结尾的页码是不固定的。
3.224.220.101 - - [17/Jul/2024:12:15:31 +0000] "GET /?vid?js_html/page/212/page/5/page/3/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/6/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/6/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/6/page/6/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/231/page/3/page/232/page/232/page/232/page/232/page/232/page/5/page/4/page/3/page/3/page/232/page/2/page/2 HTTP/1.1" 200 53124 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/600.2.5 (KHTML, like Gecko) Version/8.0.2 Safari/600.2.5 (Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot)"
求助:我无法阻止这俩爬虫的请求返回目录
我遇到了个问题,前面我用阻止了 xmlrpc.php 的请求,对它的请求会产生一条错误日志放进 error.log 里:
location ~* /xmlrpc.php {
deny all;
}但是上面俩爬虫所请求的网址却无法这么操作,因为它们请求的路径是根路径,也就是 location /,所以无法通过 location 来识别它们。
使用变量 $query_string 或 $request_uri 可以匹配它们,但是在 if 语句里不能使用 deny 命令,只能 return 或 rewrite,这无法阻止它们的请求,只是改变了请求的处理结果。
如下:
if ( $query_string ~* "namespace=|vid" ) {
# 或者
if ( $request_uri ~* "\?namespace=|\?vid" )
return 404;
# 不能使用 deny all; 否则会导致配置文件产生错误
}把上面的代码添加到 location / 前面就可以生效了。但是请求依然是完成的只是状态码变成 404 了,并没有阻止请求。同时它们的日志依然在 access.log 里,这在我查看日志时造成了严重的干扰。不知道有没有大神能指导下,怎样可以直接 deny 掉它们。
不过这样也节省了些资源,因为我的博客的通用配置是 404 时跳转到首页,现在这俩网址会单纯的返回 404,而非返回网站首页。
相关知识:
上面的配置里用到了两个 nginx 的变量,$query_string 是网址里的查询字符串,也就是问号后面的部分,而 $request_uri 是完整的请求网址。所以它们匹配的正则部分有所区别, 因为 $query_string 里是没有网址最前面的 /? 的。
nginx 变量的文档:https://nginx.org/en/docs/varindex.html
ngixn 中 location 不同匹配模式的使用:https://segmentfault.com/a/1190000022315733
error.log返回目录
这个更是重量级,全是各种扫站的,每个 ip 的翻几页都翻不完,我就不上图了。
有一些勤劳的小蜜蜂:
- 101 开头的 IP 忙着访问各种不存在的目录;
- 64 开头的 IP 不停地尝试访问各种名称的 php 文件;
- 103 开头的也在不停地尝试访问各种名称的 php 文件,不过它主要访问根目录的,上面的那个仁兄多是针对 WordPress 的目录结构去访问目录里的 php 文件。
- 92 开头的在不停地尝试访问另一个网站里的各种配置文件
哈哈,大家还真是热情呢,真是八仙过海各显神通啊😅不知道我这小小的服务器能不能伺候的过来各位大爷啊
还有前面提到的 xmlrpc.php,只一页日志里就有 4 个 IP 段的来做贡献,不过现在频率低了很多,也许是被禁止后它们放弃做无用功了。
这就很头疼了,就算禁掉它们的 ip,以后也会有其他 ip 的来扫,这可如何是好呢?
闲来无事看看 Nginx 日志
-
 Google Chrome 126
Google Chrome 126 Windows 10/11
Windows 10/11 -
Google Chrome 126Windows 10/11
难绷
-
Google Chrome 126Windows 10/11
之前俺也用WP,不过现在用Halo了,它发出请求都是走的API,http://xxx.com/apis/api.halo.run/v1alpha1/
用到现在没有被攻击过和乱扫...
不过WP的主流且插件丰富,建站首选了简直是。
-
Google Chrome 126Windows 10/11
现在halo似乎越来越流行了~
-
-
Google Chrome 126Windows 10/11
网络上针对php的攻击真的多。
我的小破站现在已经完全放弃了php,仍然每天能收到大量针对php的攻击。所以后来我直接把.php的访问全给封杀了。
针对amazon的爬虫,我觉得反正流量也不是从amazon来的,如果某个IP访问数异常了就直接针对IP干掉了。-
Google Chrome 126Windows 10/11
刚才看了下日志,Facebook 和 Amazon 的爬虫还在爬那些网址(即使我已经持续返回 404)。它们有多个 ip 所以不好封禁,只好先维持现状了
-
-
Google Chrome 126
 GNU/Linux x64
GNU/Linux x64 我也不知道怎么禁用,但是if里面应该是可以禁用或分割日志的

你看看那几个ip是不是从上海或者北京来的。是的话就验证我的猜想了